Resume
Обратная связь:
почта - it38dato@yandex.ru, телеграмм - @it38dato.
Show more
Обо мне
Инженер-программист, г. Иркутск. Я специалист в области информационных технологий с более 5 лет опыта в администрировании баз данных, локальных, виртуальных и облачных серверов и в разработке программного обеспечения. Для саморазвития я в свободное время читаю и перевожу техническую документацию на английском языке, администрирую свой веб-сервер http://dato138it.ru, дорабатываю свои проекты https://github.com/it38dato и решаю задачи на фрилансе. Мне интересно работать в команде, активно развиваться в программировании и администрировании, изучать новые технологии.
Навыки:
Html, Css, Js, Спутниковые радионавигационные системы, С++, Виртуализация, Linux, Bash, Windows, Python, English, Sql, Clouds, Docker, Ericsson, Nokia, Vba.
Услуги:
# Верстка Веб-страниц.
# Разработка Парсинг данных.
# Анализ сетевых технологий.
# Администрирование локальных серверов.
# Администрирование виртуальных серверов.
# Администрирование локальных сетей.
# Администрирование Веб-серверов.
# Разработка Автоматизация установки и настройки ПО.
# Разработка Восстановление флешки.
# Написание Sql запросов.
# Администрирование баз данных.
# Разработка баз данных.
# Разработка Бэкап.
2018-03-01 - 2022-11-01: Всероссийский государственный университет юстиции, Иркутск. Должность: Технический специалист. Достижения: В рамках "Импортозамещения с Windows на Linux" настроил виртуальный сервер с Linux системой и развернул в нем раздачу по сети установщика образа на компьютеры, на что сэкономило время на установку Linux в компьютерных классах Дополнительная информация: Обязанности - работа с сайтами, поддержка функционирования серверов и сервисов СУБД, техническая поддержка пользователей. Навыки - Виртуализация, Linux, Windows.
Show more
Services:
# Администрирование виртуальных серверов.
# Администрирование локальных серверов.
# Разработка скрипта Автоматизация установки и настройки ПО.
# Разработка скрипта Восстановление флешки.
# Разработка Sql таблиц Инвентаризация техники.
# Написание Sql запросов.
# Администрирование базы данных.
Task:
Установить Hyper-V в Windows Server 2012 c помощью Shell.
# Администрирование виртуальных серверов.
Decision:
PS C:\Windows\system32> Get-Module -ListAvailable
ModuleType Version Name ExportedCo
---------- ------- ---- ----------
...
Binary 1.1 Hyper-V {Add-VMDvd
...
PS C:\Windows\system32> Import-Module -Name Hyper-V
Task:
Развернуть виртуальную тестовую машину Redos в Hyber-v с помощью Powershell.
# Администрирование виртуальных серверов.
Decision:
PS C:\Windows\system32> Get-VM
Name State CPUUsage(%) MemoryAssigned(M) Uptime Status
---- ----- ----------- ----------------- ------ ------
Alt Off 0 0 00:00:00 Работает нормально
PS C:\Windows\system32> $ram=1*1024*1024*1024
PS C:\Windows\system32> $ram
1073741824
PS C:\Windows\system32> $hdd=10*1024*1024*1024
PS C:\Windows\system32> $hdd
10737418240
PS C:\Windows\system32> NEW-VM -Name Redos -MemoryStartupBytes $ram -NewVHDPath 'C:\Data\VM\Redos\Redos.vhdx'-NewVHD
SizeBytes $hdd -Path 'C:\Data\VM\Redos'
Name State CPUUsage(%) MemoryAssigned(M) Uptime Status
---- ----- ----------- ----------------- ------ ------
Redos Off 0 0 00:00:00 Работает нормально
PS C:\Windows\system32> Get-VM
Name State CPUUsage(%) MemoryAssigned(M) Uptime Status
---- ----- ----------- ----------------- ------ ------
Alt Off 0 0 00:00:00 Работает нормально
Redos Off 0 0 00:00:00 Работает нормально
PS C:\Windows\system32> Start-VM -name Redos
PS C:\Windows\system32> Get-VM
Name State CPUUsage(%) MemoryAssigned(M) Uptime Status
---- ----- ----------- ----------------- ------ ------
Alt Off 0 0 00:00:00 Работает нормально
Redos Running 0 1024 00:00:16 Работает нормально
PS C:\Windows\system32> Stop-VM Redos
Подтверждение
Hyper-V не удается завершить работу виртуальной машины Redos, так как служба интеграции по завершению работы недоступна.
Во избежание потенциальной потери данных вы можете приостановить виртуальную машину или сохранить ее состояние. Другим
вариантом является отключение виртуальной машины, но при этом возможна потеря данных.
[Y] Да - Y [N] Нет - N [S] Приостановить - S [?] Справка (значением по умолчанию является "Y"): y
PS C:\Windows\system32> Get-VM
Name State CPUUsage(%) MemoryAssigned(M) Uptime Status
---- ----- ----------- ----------------- ------ ------
Alt Off 0 0 00:00:00 Работает нормально
Redos Off 0 0 00:00:00 Работает нормально
Task:
Установить и настроить дистрибутив Redos в виртуальной машине.
# Администрирование виртуальных серверов.
Decision:
- выбираем Install - выбрать размер разделов - поменяем систему разметки LVM на Standart Portition - нажимаем на click here to create them autmaticaly - установщик автоматически разделит диск - уменьшить размер корневого раздела / и раздел /home - Меняю у них размеры - Done - интернет настроить в Network & Host Name - Ethernet переключаем тумблер - Done - software Slection - minmal install- Done - запуск
Task:
Установить виртуальный сервер AltLinux в Hyper-V.
# Администрирование виртуальных серверов.
Decision:
PS C:\Windows\system32> $ram=1*1024*1024*1024
PS C:\Windows\system32> $ram
1073741824
PS C:\Windows\system32> $hdd=10*1024*1024*1024
PS C:\Windows\system32> $hdd
10737418240
PS C:\Windows\system32> NEW-VM -Name Alt -MemoryStartupBytes $ram -NewVHDPath 'C:\Data\VM\Alt\Alt.vhdx'-NewVHD
SizeBytes $hdd -Path 'C:\Data\VM\Alt'
PS C:\Windows\system32> Start-VM -name Alt
PS C:\Windows\system32> Get-VM
Name State CPUUsage(%) MemoryAssigned(M) Uptime Status
---- ----- ----------- ----------------- ------ ------
Alt Off 0 0 00:00:00 Работает нормально
Task:
Ввод компьютера в домен Windows и изменение имени хоста.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# yum install join-to-domain
[root@hvredos ~]# join-to-domain.sh
[root@hvredos ~]# reboot
[root@hvredos ~]# hostname hvredos.tdomain.ru
[root@hvredos ~]# hostname
hvredos.tdomain.ru
[root@hvredos ~]# vim /etc/hostname
[root@hvredos ~]# cat /etc/hostname
hvredos.tdomain.ru
[root@hvredos ~]# vim /etc/hosts
[root@hvredos ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 hvredos.tdomain.ru hvredos
Task:
Установка Консультант Плюс и подключение сетевых директорий с использованием automount и механизма Kerberos.
- Для подключения скрытых сетевых каталогов необходимо экранировать символ $.
- В файле /etc/krb5.conf нужно закомментировать строку (если она ещё не закомментирована).
- Создать ярлык Консультант +. В случае замедленной работы можно добавить ключ /sprocess=0. При нормальной работе, не добавляйте этот ключ. Ключ /yes необходим для подавления сообщения об ошибке [WNetGetUniversalName ...] : NO_NETWORK
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# yum install wine winetricks
# winetricks riched30 winhttp
- Wine - Wine Configuration - Графика - уберите галочку в пункте "Разрешить менеджеру окон декорировать окна". - Для запуска «Консультант Плюс» на рабочей станции подключите сетевой диск с «Консультантом» - Сделать это можно с помощью подключения сетевых директорий с использованием automount и механизма Kerberos
[root@hvredos ~]# smbclient -L hvredos -k
Sharename Type Comment
--------- ---- -------
Consultant Disk
ConsultantR Disk
S Disk
...
[root@hvredos ~]# yum install cifs-utils autofs
[root@hvredos ~]# klist
Ticket cache: FILE:/tmp/krb5cc_1
Default principal: tuser@tdomain.ru
Valid starting Expires service principal
31.08.2020 09:51:47 31.08.2020 19:51:47 krbtgt/tdomain.ru@tdomain.ru
renew until 31.08.2020 19:51:47
[root@hvredos ~]# vim /etc/auto.master
[root@hvredos ~]# cat /etc/auto.master
...
/mnt/.hpwindows /etc/auto.samba --ghost
[root@hvredos ~]# vim /etc/auto.samba
[root@hvredos ~]# cat /etc/auto.samba
Students -fstype=cifs,multiuser,cruid=tuser,sec=krb5,domain=tdomain.ru,vers=2.1 ://hpwindows/Students
[root@hvredos ~]# vim /etc/auto.samba
[root@hvredos ~]# cat /etc/auto.samba
Consultant -fstype=cifs,multiuser,cruid=tuser,sec=krb5,domain=tdomain.ru,vers=2.1 ://hpwindows/Consultant\$
[root@hvredos ~]# cat /etc/krb5.conf
...
default_ccache_name = KEYRING:persistent:%{uid}
...
[root@hvredos ~]# vim/etc/krb5.conf
[root@hvredos ~]# cat /etc/krb5.conf
...
default_ccache_name = FILE:/tmp/krb5cc_%{uid}
...
[root@hvredos ~]# systemctl start autofs.service
[root@hvredos ~]# systemctl enable autofs --now
[root@hvredos ~]# ls /mnt/.hpwindows/Consultant/
... cons.exe ...
[root@hvredos ~]# winecfg
[root@hvredos ~]# wine /mnt/.hpwindows/Сonsultant/cons.exe /linux /yes
[root@hvredos ~]# vim /home/tuser@tdomain.ru/Рабочий\ стол/Consultant.desktop
[root@hvredos ~]# cat /home/tuser@tdomain.ru/Рабочий\ стол/Consultant.desktop
[Desktop Entry]
Name=ConsultantPlus
Exec=wine /mnt/.hpwindows/Сonsultant/cons.exe
Type=Application
StartupNotify=true
Comment=ConsultantPlus
icon=43D4_Cons.0
StartupWMClass=c.exe
Task:
Создание ярлыка для сетевой директории
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# ln -s /mnt/.hvredos/S /home/tuser@tdomain.ru/Рабочий\ стол/S
Task:
Oграничение доступа к USB накопителям.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# vim /etc/udev/rules.d/99-usb.rules
[root@hvredos ~]# cat /etc/udev/rules.d/99-usb.rules
ENV{ID_USB_DRIVER}=="usb-storage",ENV{UDISKS_IGNORE}="1"
# udevadm control --reload-rules
Task:
Запрет создания ярлыков и файлов на рабочем столе.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# tune2fs -l /dev/sda1 | grep "Default mount options:"
Default mount options: user_xattr acl
[root@hvredos ~]# vim /home/tuser@tdomain.ru/.config/user-dirs.dirs
[root@hvredos ~]# cat /home/tuser@tdomain.ru/.config/user-dirs.dirs
# This file is written by xdg-user-dirs-update
# If you want to change or add directories, just edit the line you're
# interested in. All local changes will be retained on the next run
# Format is XDG_xxx_DIR="$HOME/yyy", where yyy is a shell-escaped
# homedir-relative path, or XDG_xxx_DIR="/yyy", where /yyy is an
# absolute path. No other format is supported.
#
XDG_DESKTOP_DIR="$HOME/Рабочий стол"
XDG_DOWNLOAD_DIR="$HOME/Загрузки"
XDG_TEMPLATES_DIR="$HOME/Шаблоны"
XDG_PUBLICSHARE_DIR="$HOME/Общедоступные"
XDG_DOCUMENTS_DIR="$HOME/Документы"
XDG_MUSIC_DIR="$HOME/Музыка"
XDG_PICTURES_DIR="$HOME/Изображения"
XDG_VIDEOS_DIR="$HOME/Видео"
[root@hvredos ~]# ls -la /home/tuser@tdomain.ru/.config
...
-rw-------. 1 tuser ïîëüçîâàòåëè äîìåíà 714 àâã 31 09:52 user-dirs.dirs
-rw-r--r--. 1 tuser ïîëüçîâàòåëè äîìåíà 5 àâã 31 09:52 user-dirs.locale
[root@hvredos ~]# chown root:root /home/tuser@tdomain.ru/.config/user-dirs.dirs
[root@hvredos ~]# ls -la /home/tuser@tdomain.ru/.config
...
-rw-------. 1 root root 714 àâã 31 09:52 user-dirs.dirs
-rw-r--r--. 1 tuser ïîëüçîâàòåëè äîìåíà 5 àâã 31 09:52 user-dirs.locale
[root@hvredos ~]# ls -la
...
drwxr-xr-x. 2 tuser ïîëüçîâàòåëè äîìåíà 4096 àâã 31 09:52 'Рабочий стол'
...
[root@hvredos ~]# chown -R root:root /home/tuser@tdomain.ru/Рабочий\ стол/
[root@hvredos ~]# ls -la
...
drwxr-xr-x. 2 root root 4096 àâã 31 09:52 'Рабочий стол'
drwxr-xr-x. 2 tuser ïîëüçîâàòåëè äîìåíà 4096 àâã 31 09:52 Øàáëîíû
Task:
Как скрыть пользователей от экрана входа.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# cat /var/lib/AccountsService/users/user
[User]
Language=
XSession=
SystemAccount=false
[root@hvredos ~]# vim /var/lib/AccountsService/users/user
[root@hvredos ~]# cat /var/lib/AccountsService/users/user
[User]
Language=
XSession=gnome
SystemAccount=true
Task:
Добавление пользователя из доменной сети.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# vim /var/lib/AccountsService/users/user
[root@hvredos ~]# cat /var/lib/AccountsService/users/user
[User]
Language=
XSession=
Icon=/home/tuser@tdomain.ru/.face
SystemAccount=false
Task:
Отключить сетевые принтеры.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# vim /etc/avahi/avahi-daemon.conf
cat /etc/avahi/avahi-daemon.conf
# This file is part of avahi.
...
enable-dbus=no
...
[root@hvredos ~]# reboot
Task:
Настройка оповещения и автоматического обновления пакетов в РЕД ОС с помощью yum-cron.
- Если не требуется обновлять определенные пакеты (как вручную, так и автоматически), то добавляем их в исключение. Например, kernel и php.
- Если не требуется обновлять пакеты ТОЛЬКО в автоматическом режиме, тогда в /etc/yum/yum-cron.conf , в раздел [base]
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# yum -y install yum-cron
[root@hvredos ~]# vim /etc/yum/yum-cron.conf
[root@hvredos ~]# cat /etc/yum/yum-cron.conf
[commands]
...
apply_updates = no
[root@hvredos ~]# vim /etc/yum/yum-cron.conf
[root@hvredos ~]# cat /etc/yum/yum-cron.conf
[commands]
...
apply_updates = yes
[root@hvredos ~]# systemctl enable yum-cron --now
[root@hvredos ~]# nano /etc/yum.conf
exclude=kernel, php
[root@hvredos ~]# nano /etc/yum/yum-cron.conf
exclude=kernel* php*
Task:
Развернуть Pxe сервер для развертывания Redos с загрузкой в Uefi по сети.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# ifconfig
enp2s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet tipwindowsserver netmask Mask1 broadcast IpAddr.255
...
[root@hvredos ~]# dnf install dhcp tftp-server syslinux httpd dnf-plugins-core -y
[root@hvredos ~]# mkdir /var/lib/tftpboot/pxelinux.cfg
[root@hvredos ~]# mkdir /var/lib/tftpboot/uefi
[root@hvredos ~]# mkdir -p /var/lib/tftpboot/images/REDOS
[root@hvredos ~]# cp /usr/share/syslinux/{chain.c32,mboot.c32,memdisk,menu.c32,pxelinux.0,ldlinux.c32,libutil.c32} /var/lib/tftpboot/
[root@hvredos ~]# chmod 777 /var/lib/tftpboot/pxelinux.0
[root@hvredos ~]# dnf download shim-x64 grub2-efi-x64 --downloaddir=/root/
[root@hvredos ~]# cd /root/
[root@hvredos ~]# rpm2cpio shim-x64-*.rpm | cpio -dimv
[root@hvredos ~]# rpm2cpio grub2-efi-x64-*.rpm | cpio -dimv
[root@hvredos ~]# cp ./boot/efi/EFI/BOOT/BOOTX64.EFI /var/lib/tftpboot/uefi
[root@hvredos ~]# cp ./boot/efi/EFI/redos/grubx64.efi /var/lib/tftpboot/uefi
[root@hvredos ~]# chmod 777 /var/lib/tftpboot/uefi/*.*
[root@hvredos ~]# umount -t iso9660 -o loop redos-MUROM-7.3.2-20211027.0-Everything-x86_64-DVD1.iso /mnt/
[root@hvredos ~]# cp -vR /mnt/* /var/lib/tftpboot/images/REDOS/
[root@hvredos ~]# umount /mnt/
[root@hvredos ~]# vim /etc/dhcp/dhcpd.conf
[root@hvredos ~]# cat /etc/dhcp/dhcpd.conf
non-authoritative;
allow bootp;
option space pxelinux;
option pxelinux.magic code 208 = string;
option pxelinux.configfile code 209 = text;
option pxelinux.pathprefix code 210 = text;
option pxelinux.reboottime code 211 = unsigned integer 32;
option architecture-type code 93 = unsigned integer 16;
subnet tipwindowsserver.0 netmask Mask1 {
option routers tipwindowsserver;
range tipwindowsserver.70 tipwindowsserver.80;
class "pxeclients" {
match if substring (option vendor-class-identifier, 0, 9) = "PXEClient";
next-server tipwindowsserver;
if option architecture-type = 00:07 {
filename "uefi/grubx64.efi";
}
else {
filename "pxelinux.0";
}
}
}
# systemctl enable dhcpd --now
[root@hvredos ~]# vim /var/lib/tftpboot/pxelinux.cfg/default
[root@hvredos ~]# cat /var/lib/tftpboot/pxelinux.cfg/default
default menu.c32
PROMPT 0
TIMEOUT 150
MENU TITLE PXE Menu
LABEL REDOS 7.3
MENU LABEL REDOS 7.3
KERNEL images/REDOS/images/pxeboot/vmlinuz
APPEND initrd=images/REDOS/images/pxeboot/initrd.img ramdisk_size=128000 ip=dhcp inst.repo=http://tipwindowsserver/images/REDOS/
[root@hvredos ~]# vim /var/lib/tftpboot/uefi/grub.cfg
[root@hvredos ~]# cat /var/lib/tftpboot/uefi/grub.cfg
function load_video {
insmod efi_gop
insmod efi_uga
insmod video_bochs
insmod video_cirrus
insmod all_video
}
load_video
set gfxpayload=keep
insmod gzio
menuentry 'REDOS 7.3' {
linux images/REDOS/images/pxeboot/vmlinuz ip=dhcp inst.repo=http://tipwindowsserver/images/REDOS/
initrd images/REDOS/images/pxeboot/initrd.img
}
Task:
Используем web-сервер для публикации файлов дистрибутива РЕД ОС в локальной сети.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# vim /etc/httpd/conf.d/pxeboot.conf
[root@hvredos ~]# cat /etc/httpd/conf.d/pxeboot.conf
Alias /images /var/lib/tftpboot/images
<Directory /var/lib/tftpboot/images>
Options Indexes FollowSymLinks
Require ip 127.0.0.1 tipwindowsserver.0/24
</Directory>
[root@hvredos ~]# systemctl enable httpd --now
Task:
Настройка и запуск службы tftp.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# vim /usr/lib/systemd/system/tftp.service
[root@hvredos ~]# cat /usr/lib/systemd/system/tftp.service
...
[Install]:
WantedBy=multi-user.target
Also=tftp.socket
...
[root@hvredos ~]# vim /usr/lib/systemd/system/tftp.socket
[root@hvredos ~]# cat /usr/lib/systemd/system/tftp.socket
...
[Unit]
Description=Tftp Server Activation Socket
[Socket]
ListenDatagram=0.0.0.0:69
[Install]
WantedBy=sockets.target
...
[root@hvredos ~]# systemctl daemon-reload
[root@hvredos ~]# systemctl enable tftp --now
[root@hvredos ~]# ausearch -c 'httpd' --raw | audit2allow -M my-httpd
[root@hvredos ~]# semodule -i my-httpd.pp
Task:
Автоматизация развертывания (kickstart)
Создать файл kickstart, Записать файл на локальный или удаленный носитель, Создать загрузочный диск, с которого будет запускаться установка, Предоставить доступ к установочной структуре, Начать процесс установки.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# dnf install pykickstart -y
[root@hvredos ~]# cp /root/anaconda-ks.cfg /var/lib/tftpboot
[root@hvredos ~]# mv /var/lib/tftpboot/anaconda-ks.cfg /var/lib/tftpboot/ks.cfg
[root@hvredos ~]# vim /var/lib/tftpboot/pxelinux.cfg/default
[root@hvredos ~]# cat /var/lib/tftpboot/pxelinux.cfg/default
...
APPEND initrd=images/REDOS/images/pxeboot/initrd.img ramdisk_size=128000 ip=dhcp method=http://tipwindowsserver/images/REDOS/ devfs=nomount inst.ks=http://tipwindowsserver/ks.cfg
[root@hvredos ~]# vim /var/lib/tftpboot/uefi/grub.cfg
[root@hvredos ~]# cat /var/lib/tftpboot/uefi/grub.cfg
... {
linux images/REDOS/images/pxeboot/vmlinuz ip=dhcp kernel vmlinuz inst.repo=http://tipwindowsserver/images/REDOS/ inst.ks=http://tipwindowsserver/ks.cfg
initrd images/REDOS/images/pxeboot/initrd.img
}
[root@hvredos ~]# vim /var/lib/tftpboot/ks.cfg
[root@hvredos ~]# cat /var/lib/tftpboot/ks.cfg
# Здесь указываем раскладку клавиатуры
keyboard --vckeymap=us --xlayouts='us','ru' --switch='grp:alt_shift_toggle'
# Системная локаль
lang ru_RU.UTF-8
# Информация о сетевом интерфейсе и имя машины
network --bootproto=dhcp --device=enp2s0 --noipv6 --activate
network --hostname=hostname1337
# Пароль Root представлен в виде хэш-суммы
rootpw --iscrypted $6$DUu0yyOYMRbGS8gL$9zHYPsxROGEZdDKG0wnf7h8SGnKOp3V272De6oGTVUsz2uBLmEeiR6T6cInRN5dyWcxNXh5fVluEUTQ/3rmzB0
# Настройка сервисов (в данном случае сервис по обновлению меток времени и дат)
services --enabled="chronyd"
# Настройка временной зоны
timezone Europe/Moscow --isUtc
#Настройка локального пользователя
user --groups=wheel --name=mekka --password=$6$83fyYZ7KMS7G9t6A$E5/99/ffOwjUOo8THr1ngqGDdKMimpTZf3IT9S/SI98BTV7dta7GksLYnQEZjtqqyZQrwibSRlvYccRqHB7m8/ --iscrypted --gecos="Mekka"
# Настройка xorg при загрузке
xconfig --startxonboot
# Указание загрузочного сектора и тип структуры
bootloader --location=mbr --boot-drive=sda
# Удаление всей информации с партиций для последующей установки
clearpart --none --initlabel
# Здесь указана вся разметка диска
part /boot --fstype="xfs" --onpart=sda2
part biosboot --fstype="biosboot" --noformat --onpart=sda4
part pv.31 --fstype="lvmpv" --noformat --onpart=sda3
part /boot/efi --fstype="efi" --onpart=sda1 --fsoptions="umask=0077,shortname=winnt"
volgroup ro --noformat --useexisting
logvol swap --fstype="swap" --useexisting --name=swap --vgname=ro
logvol /home --fstype="xfs" --noformat --useexisting --name=home --vgname=ro
logvol / --fstype="ext4" --useexisting --name=root --vgname=ro
#дополнительные пакеты для установки
%packages
@^mate-desktop-environment
@backup-client
@base
@branding
@core
@desktop-debugging
@dial-up
@directory-client
@fonts
@guest-agents
@guest-desktop-agents
@input-methods
@internet-applications
@internet-browser
@java-platform
@mate-desktop
@multimedia
@network-file-system-client
@print-client
@x11
chrony
%end
#настройка аварийных дампов памяти в случае сбоев (оставить как есть)
%addon com_redhat_kdump --enable --reserve-mb='auto'
%end
#настройка анаконды (оставить как есть)
%anaconda
pwpolicy root --minlen=6 --minquality=1 --notstrict --nochanges --notempty
pwpolicy user --minlen=6 --minquality=1 --notstrict --nochanges --emptyok
pwpolicy luks --minlen=6 --minquality=1 --notstrict --nochanges --notempty
%end
Task:
Настройка установки РЕД ОС по PXE через VNC вместо Kickstart.
# Администрирование локальных серверов.
Decision:
[root@hvredos ~]# vim /var/lib/tftpboot/pxelinux.cfg/default
[root@hvredos ~]# cat /var/lib/tftpboot/pxelinux.cfg/default
...
APPEND initrd=images/REDOS/images/pxeboot/initrd.img ramdisk_size=128000 ip=dhcp method=http://tipwindowsserver/images/REDOS/ devfs=nomount inst.vnc inst.vncpassword=tpassword
[root@hvredos ~]# vim /var/lib/tftpboot/uefi/grub.cfg
[root@hvredos ~]# cat /var/lib/tftpboot/uefi/grub.cfg
... {
linux images/REDOS/images/pxeboot/vmlinuz ip=dhcp kernel vmlinuz inst.repo=http://tipwindowsserver/images/REDOS/ inst.vnc inst.vncpassword=tpassword
initrd images/REDOS/images/pxeboot/initrd.img
}
Source:
# https://redos.red-soft.ru/base/other-soft/other-other/consultant/?sphrase_id=53349
# https://wtuseri.astralinutdomain.ru/pages/viewpage.action?pageId=61574227
# https://askubuntu.ru/questions/21203/kak-skry-t-pol-zovatelej-ot-e-krana-vxoda-v-gdm
# https://computingforgeeks.com/how-to-install-gimp-on-centos-rhel-8-desktop/
# https://ru.wtuserihow.com/%D1%81%D0%BE%D0%B7%D0%B4%D0%B0%D1%82%D1%8C-ISO-%D1%84%D0%B0%D0%B9%D0%BB-%D0%B2-Linux
# https://losst.ru/zapis-diskov-v-ubuntu
# https://losst.ru/luchshie-analogi-paint-dlya-linux
# https://computingforgeeks.com/how-to-install-anydesk-on-centos-rhel-8/
Task:
Set up an ActiveDirectory/Login.
# Администрирование локальных серверов.
Decision:
root@hvalt:~# apt-get install task-auth-ad-sssd
root@hvalt:~# net time set -S tdomain.ru
# system-auth write ad tdomain.ru hvalt hvalt 'tuser' 'tpassword'
Using short domain name -- hvalt
Joined 'hvalt' to dns domain 'tdomain.ru'
Successfully registered hostname with DNS
failed to call wbcGetDisplayName: WBC_ERR_WINBIND_NOT_AVAILABLE
Could not lookup sid S-1-5-21-965402400-3010625364-1855727791-513
failed to call wbcGetDisplayName: WBC_ERR_WINBIND_NOT_AVAILABLE
Could not lookup sid S-1-5-21-965402400-3010625364-1855727791-512
root@hvalt:~# wbinfo -t
checking the trust secret for domain hvredos via RPC calls succeeded
root@hvalt:~# acc
2 keyboards found
qt.qpa.xcb: could not connect to display
qt.qpa.plugin: Could not load the Qt platfohvredos plugin "xcb" in "" even though it was found.
This applhvredosation failed to start because no Qt platfohvredos plugin could be initialized. Reinstalling the applhvredosation may fix this problem.
Available platfohvredos plugins are: eglfs, linuxfb, minimal, minimalegl, offscreen, vnc, xcb.
root@hvalt:~# exit
root@hvalt:~# exit
[root@hvredos ~]# ssh -X tuser@hvalt
root@hvalt:~# su -
root@hvalt:~# acc
2 keyboards found
QStandardPaths: XDG_RUNTIME_DIR not set, defaulting to '/tmp/.private/root/runtime-root'
libpng warning: hvredosCP: known incorrect sRGB profile
libpng warning: hvredosCP: known incorrect sRGB profile
libpng warning: hvredosCP: known incorrect sRGB profile
libpng warning: hvredosCP: known incorrect sRGB profile
libpng warning: hvredosCP: known incorrect sRGB profile
WARNING: (alterator lookout evaluation): imported module (alterator presentation events) overrides core binding `when'
libpng warning: hvredosCP: known incorrect sRGB profile
libpng warning: hvredosCP: known incorrect sRGB profile
libpng warning: hvredosCP: known incorrect sRGB profile
libpng warning: hvredosCP: known incorrect sRGB profile
root@hvalt:~# vim /etc/net/ifaces/eth0/resolv.conf
root@hvalt:~# cat /etc/net/ifaces/eth0/resolv.conf
nameserver tipwindowsserver
root@hvalt:~# hostnamectl set-hostname hvalt.tdomain.ru
root@hvalt:~# cat /etc/resolv.conf
search tdomain.ru
nameserver 127.0.0.1
root@hvalt:~# vim /etc/resolv.conf
root@hvalt:~# cat /etc/resolv.conf
# Configuration for resolv(8)
# See resolv.conf(5) for details
resolv_conf_head='# Do not edit manually, use\n# /etc/net/ifaces/<interface>/resolv.conf instead.'
resolv_conf=/etc/resolv.conf
# These interfaces will always be processed first.
interface_order='lo lo[0-9]* lo.*'
# These interfaces will be processed next, unless they have a metrhvredos.
dynamhvredos_order='tap[0-9]* tun[0-9]* vpn vpn[0-9]* wg[0-9]* ppp[0-9]* ippp[0-9]*'
#Configuration files for named subscriber.
named_zones=/var/lib/bind/etc/resolv-zones.conf
named_options=/var/lib/bind/etc/resolv-options.conf
#Configuration files for dnsmasq subscriber.
dnsmasq_conf=/etc/dnsmasq.conf.d/60-resolv
dnsmasq_resolv=/etc/resolv.conf.dnsmasq
name_servers=127.0.0.1
root@hvalt:~# vim /etc/resolv.conf
root@hvalt:~# cat /etc/resolv.conf
# Configuration for resolv(8)
# See resolv.conf(5) for details
resolv_conf_head='# Do not edit manually, use\n# /etc/net/ifaces/<interface>/resolv.conf instead.'
resolv_conf=/etc/resolv.conf
# These interfaces will always be processed first.
#interface_order='lo lo[0-9]* lo.*'
interface_order='lo lo[0-9]* lo.* eth0'
search_domains=tdomain.ru
# These interfaces will be processed next, unless they have a metrhvredos.
dynamhvredos_order='tap[0-9]* tun[0-9]* vpn vpn[0-9]* wg[0-9]* ppp[0-9]* ippp[0-9]*'
#Configuration files for named subscriber.
named_zones=/var/lib/bind/etc/resolv-zones.conf
named_options=/var/lib/bind/etc/resolv-options.conf
#Configuration files for dnsmasq subscriber.
dnsmasq_conf=/etc/dnsmasq.conf.d/60-resolv
dnsmasq_resolv=/etc/resolv.conf.dnsmasq
#name_servers=127.0.0.1
root@hvalt:~# resolv -u
root@hvalt:~# cat /etc/resolv.conf
# Generated by resolv
# Do not edit manually, use
# /etc/net/ifaces/<interface>/resolv.conf instead.
search tdomain.ru
nameserver tipwindowsserver
...
nameserver 8.8.8.8
root@hvalt:~# hostname
hvalt.tdomain.ru
root@hvalt:~# dig _kerberos._udp.tdomain.ru SRV | grep ^_kerberos
_kerberos._udp.tdomain.ru. 600 IN SRV 0 100 88 M-1.tdomain.ru.
...
_kerberos._udp.tdomain.ru. 600 IN SRV 0 100 88 T-1.tdomain.ru.
root@hvalt:~# dig _kerberos._tcp.tdomain.ru SRV | grep ^_kerberos
_kerberos._tcp.tdomain.ru. 600 IN SRV 0 100 88 M-c.tdomain.ru.
...
_kerberos._tcp.tdomain.ru. 600 IN SRV 0 100 88 T-1.tdomain.ru.
root@hvalt:~# cat /etc/krb5.conf | grep default_realm
default_realm = tdomain.ru
# default_realm = EXAMPLE.COM
root@hvalt:~# cat /etc/krb5.conf | grep dns_lookup_realm
dns_lookup_realm = false
root@hvalt:~# cat /etc/krb5.conf | grep dns_lookup_kdc
dns_lookup_kdc = true
root@hvalt:~# exit
[root@hvredos ~]# ssh -X tuser@hvalt
root@hvalt:~# kinit tuser
root@hvalt:~# klist
Thvredosket cache: KEYRING:persistent:0:krb_ccache_CCjHpN1
Default principal: a-r@tdomain.ru
Valid starting Expires Servhvredose principal
10.08.2022 12:30:34 10.08.2022 22:30:34 krbtgt/tdomain.ru@tdomain.ru
renew until 17.08.2022 12:30:32
root@hvalt:~# apt-get install samba-client
root@hvalt:~# cat /etc/samba/smb.conf | grep realm
realm = tdomain.ru
root@hvalt:~# cat /etc/samba/smb.conf | grep workgroup
workgroup = hvalt
root@hvalt:~# cat /etc/samba/smb.conf | grep netbios
netbios name = hvalt
root@hvalt:~# cat /etc/samba/smb.conf | grep security
security = ads
root@hvalt:~# cat /etc/samba/smb.conf | grep method
kerberos method = system keytab
root@hvalt:~# cat /etc/samba/smb.conf | grep idmap
idmap config * : range = 200000-2000200000
idmap config * : backend = sss
root@hvalt:~# vim /etc/samba/smb.conf
root@hvalt:~# cat /etc/samba/smb.conf | grep idmap
idmap config * : range = 200000-2000200000
; idmap config * : backend = sss
idmap config * : backend = tdb
# testpahvalt
Load smb config files from /etc/samba/smb.conf
Loaded servhvredoses file OK.
Weak crypto is allowed
Server role: ROLE_DOMAIN_MEMBER
Press enter to see a dump of your servhvredose definitions
# Global parameters
[global]
kerberos method = system keytab
machine password timeout = 0
realm = tdomain.ru
security = ADS
template homedir = /home/tdomain.ru/%U
template shell = /bin/bash
winbind use default domain = Yes
workgroup = hvredos
idmap config * : range = 200000-2000200000
idmap config * : backend = tdb
[share]
comment = Commonplace
path = /srv/share
read only = No
[homes]
browseable = No
comment = Home Directory for '%u'
read only = No
root@hvalt:~# cat /etc/hosts
127.0.0.1 localhost.localdomain localhost
root@hvalt:~# vim /etc/hosts
root@hvalt:~# cat /etc/hosts
127.0.0.1 hvalt.tdomain.ru hvalt
root@hvalt:~# net ads join -U tuser
Enter tuser's password:
Using short domain name -- hvalt
Joined 'hvalt' to dns domain 'tdomain.ru'
root@hvalt:~# klist -k -e
Keytab name: FILE:/etc/krb5.keytab
KVNO Principal
---- --------------------------------------------------------------------------
9 host/hvalt.tdomain.ru@tdomain.ru (aes256-cts-hmac-sha1-96)
9 host/hvalt@tdomain.ru (aes256-cts-hmac-sha1-96)
9 host/hvalt.tdomain.ru@tdomain.ru (aes128-cts-hmac-sha1-96)
9 host/hvalt@tdomain.ru (aes128-cts-hmac-sha1-96)
9 host/hvalt.tdomain.ru@tdomain.ru (DEPRECATED:arcfour-hmac)
9 host/hvalt@tdomain.ru (DEPRECATED:arcfour-hmac)
9 hvalt$@tdomain.ru (aes256-cts-hmac-sha1-96)
9 hvalt$@tdomain.ru (aes128-cts-hmac-sha1-96)
9 hvalt$@tdomain.ru (DEPRECATED:arcfour-hmac)
8 host/hvalt.tdomain.ru@tdomain.ru (aes256-cts-hmac-sha1-96)
8 host/hvalt@tdomain.ru (aes256-cts-hmac-sha1-96)
8 host/hvalt.tdomain.ru@tdomain.ru (aes128-cts-hmac-sha1-96)
8 host/hvalt@tdomain.ru (aes128-cts-hmac-sha1-96)
8 host/hvalt.tdomain.ru@tdomain.ru (DEPRECATED:arcfour-hmac)
8 host/hvalt@tdomain.ru (DEPRECATED:arcfour-hmac)
8 hvalt$@tdomain.ru (aes256-cts-hmac-sha1-96)
8 hvalt$@tdomain.ru (aes128-cts-hmac-sha1-96)
8 hvalt$@tdomain.ru (DEPRECATED:arcfour-hmac)
root@hvalt:~# apt-get install sssd-ad
root@hvalt:~# cat /etc/sssd/sssd.conf
[sssd]
config_file_version = 2
servhvredoses = nss, pam
# Managed by system facility command:
## control sssd-drop-privileges unprivileged|privileged|default
user = _sssd
# SSSD will not start if you do not configure any domains.
domains = tdomain.ru
[nss]
[pam]
[domain/tdomain.ru]
id_provider = ad
auth_provider = ad
chpass_provider = ad
access_provider = ad
default_shell = /bin/bash
fallback_homedir = /home/%d/%u
debug_level = 0
; cache_credentials = false
ad_gpo_ignore_unreadable = true
ad_gpo_access_control = pehvredosissive
ad_update_samba_machine_account_password = true
root@hvalt:~# vim /etc/sssd/sssd.conf
root@hvalt:~# cat /etc/sssd/sssd.conf
[sssd]
config_file_version = 2
servhvredoses = nss, pam
# Managed by system facility command:
## control sssd-drop-privileges unprivileged|privileged|default
#user = _sssd
user=root
# SSSD will not start if you do not configure any domains.
domains = tdomain.ru
[nss]
[pam]
[domain/tdomain.ru]
id_provider = ad
auth_provider = ad
chpass_provider = ad
access_provider = ad
;ldap_id_mapping = False
default_shell = /bin/bash
fallback_homedir = /home/%d/%u
debug_level = 0
;use_fully_qualified_names = True
; cache_credentials = True
ad_gpo_ignore_unreadable = true
ad_gpo_access_control = pehvredosissive
ad_update_samba_machine_account_password = true
root@hvalt:~# grep sss /etc/nsswitch.conf
passwd: files sss
shadow: tcb files sss
group: files [SUCCESS=merge] sss role
root@hvalt:~# control system-auth sss
root@hvalt:~# servhvredose sssd status
active
root@hvalt:~# servhvredose sssd start
root@hvalt:~# getent passwd tuser
tuser:*:1-9:1-3:в-н:/home/tdomain.ru/tuser:/bin/bash
root@hvalt:~# id tuser
uid=1-9(tuser) gid=1-3(пользователи домена) группы=1-3(пользователи домена),1-8(администраторы dhcp),1-0(tuser),11-0(пользователи филиалы),1-1(tuser),1-9(i-n)
root@hvalt:~# net ads info
LDAP server: IpAddr2
LDAP server name: MOW-1.tdomain.ru
Realm: tdomain.ru
Bind Path: dc=hvalt,dc=RU
LDAP port: 389
Server time: Ср, 10 авг 2022 13:08:06 +08
KDC server: IpAddr2
Server time offset: 0
Last machine account password change: Ср, 10 авг 2022 12:50:51 +08
root@hvalt:~# net ads testjoin
Join is OK
root@hvalt:~# cat /etc/lightdm/lightdm.conf | grep greeter-hide-
# greeter-hide-users = True to hide the user list
#greeter-hide-users=false
greeter-hide-users = true
root@hvalt:~# cat /etc/lightdm/lightdm-gtk-greeter.conf | grep show-language
show-language-selector = false
root@hvalt:~# cat /etc/lightdm/lightdm-gtk-greeter.conf | grep show-indhvredosators
root@hvalt:~# vim /etc/lightdm/lightdm-gtk-greeter.conf
root@hvalt:~# cat /etc/lightdm/lightdm-gtk-greeter.conf | grep show-indhvredosators
show-indhvredosators=~a11y;~power;~session;~language
root@hvalt:~# vim /etc/lightdm/lightdm-gtk-greeter.conf
root@hvalt:~# cat /etc/lightdm/lightdm-gtk-greeter.conf | grep enter-
enter-username = true
root@hvalt:~# reboot
Task:
Учетные записи и групп в Альт Линукс.
# Администрирование локальных серверов.
Decision:
root@hvalt:~# apt-get install libnss-role
root@hvalt:~# groupadd -r localadmins
groupadd: группа «localadmins» уже существует
root@hvalt:~# groupadd -r remote
groupadd: группа «remote» уже существует
root@hvalt:~# control sshd-allow-groups enabled
root@hvalt:~# sed -i 's/AllowGroups.*/AllowGroups = remote/' /etc/openssh/sshd_config
root@hvalt:~# roleadd users cdwriter cdrom audio proc radio camera floppy xgrp scanner uucp fuse
root@hvalt:~# roleadd localadmins wheel remote vboxusers
root@hvalt:~# roleadd 'Domain Users' users
Error 156: No such group
root@hvalt:~# roleadd 'Пользователи домена' users
root@hvalt:~# roleadd 'Администраторы домена' localadmins
root@hvalt:~# rolelst
users:cdwriter,cdrom,audio,proc,radio,camera,floppy,xgrp,scanner,uucp,fuse,video,vboxusers,vboxadd
localadmins:wheel,remote,vboxusers,vboxadd
пользователи домена:users
администраторы домена:localadmins
powerusers:remote,vboxadd,vboxusers
vboxadd:vboxsf
root@hvalt:~# id tuser
uid=1-9(tuser) gid=1-3(пользователи домена) группы=1-3(пользователи домена),11-0(пользователи филиалы),1-9(i-n),1-0(tuser),1-1(tuser),1-8(администраторы dhcp),100(users),80(cdwriter),22(cdrom),81(audio),19(proc),83(radio),440(camera),71(floppy),466(xgrp),467(scanner),14(uucp),483(fuse),488(video),481(vboxusers),455(vboxadd),454(vboxsf)
root@hvalt:~# roleadd 'tuser' localadmins
root@hvalt:~# roleadd 'tuser' wheel
root@hvalt:~# rolelst
users:cdwriter,cdrom,audio,proc,radio,camera,floppy,xgrp,scanner,uucp,fuse,video,vboxusers,vboxadd
localadmins:wheel,remote,vboxusers,vboxadd
пользователи домена:users
администраторы домена:localadmins
tuser:localadmins
powerusers:remote,vboxadd,vboxusers
vboxadd:vboxsf
root@hvalt:~# exit
[root@hvredos ~]# ssh -X tuser@hvalt
root@hvalt:~# id tuser
uid=1-9(tuser) gid=1-3(пользователи домена) группы=1-3(пользователи домена),11-0(пользователи филиалы),1-9(i-n),1-0(tuser),1-1(tuser),1-8(администраторы dhcp),100(users),80(cdwriter),22(cdrom),81(audio),19(proc),83(radio),440(camera),71(floppy),466(xgrp),467(scanner),14(uucp),483(fuse),488(video),481(vboxusers),455(vboxadd),454(vboxsf),101(localadmins),10(wheel),110(remote)
Task:
Добавить сетевые папки.
# Администрирование локальных серверов.
Decision:
root@hvalt:~# apt-get install autofs
root@hvalt:~# vim /etc/auto.master
root@hvalt:~# cat /etc/auto.master
# Fohvredosat of this file:
# mountpoint map options
# For details of the fohvredosat look at autofs(8).
/mnt/auto /etc/auto.tab -t 5
/mnt/net /etc/auto.avahi -t 120
/mnt/.tdirectory /etc/auto.samba --ghost
root@hvalt:~# vim /etc/auto.samba
root@hvalt:~# cat /etc/auto.samba
s -fstype=cifs,multiuser,cruid=$USER,sec=krb5,domain=tdomain.ru,vers=1.0 ://hvalt/tdirectory1
o -fstype=cifs,multiuser,cruid=$USER,sec=krb5,domain=tdomain.ru,vers=1.0 ://hvalt/tdirectory2
root@hvalt:~# systemctl enable autofs
root@hvalt:~# systemctl start autofs
root@hvalt:~# ls -la /mnt/.tdirectory/
drwxr-xr-x 4 root root 0 авг 11 14:09 .
drwxr-xr-x 5 root root 4096 авг 11 14:09 ..
d????????? ? ? ? ? ? o
d????????? ? ? ? ? ? s
Task:
Creating a Network Bridge interface.
# Администрирование локальных серверов.
Decision:
root@hvalt:~# mkdir /etc/net/ifaces/tethernet1
root@hvalt:~# cp /etc/net/ifaces/tethernet/* /etc/net/ifaces/tethernet1
root@hvalt:~# rm -f /etc/net/ifaces/tethernet/{i,r}*
root@hvalt:~# ls /etc/net/ifaces/tethernet1/
ipv4address options resolv.conf
root@hvalt:~# cat /etc/net/ifaces/tethernet1/options
BOOTPROTO=dhcp
TYPE=eth
NM_CONTROLLED=yes
DISABLED=yes
CONFIG_WIRELESS=no
SYSTEMD_BOOTPROTO=dhcp4
CONFIG_IPV4=yes
SYSTEMD_CONTROLLED=no
root@hvalt:~# vim /etc/net/ifaces/tethernet1/options
root@hvalt:~# ls /etc/net/ifaces/
default tethernet lo unknown tethernet1
root@hvalt:~# vim /etc/net/ifaces/tethernet1/options
root@hvalt:~# cat /etc/net/ifaces/tethernet1/options
BOOTPROTO=static
CONFIG_WIRELESS=no
CONFIG_IPV4=yes
HOST='tethernet'
ONBOOT=yes
TYPE=bri
root@hvalt:~# ls /etc/net/ifaces/tethernet/
ipv4address options resolv.conf
root@hvalt:~# service network restart
Source:
# https://www.altlinux.org/ActiveDirectory/Login#%D0%A3%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0_%D0%BF%D0%B0%D0%BA%D0%B5%D1%82%D0%BE%D0%B2
# https://www.altlinux.org/SSSD/AD
# https://www.altlinux.org/%D0%A1%D0%B5%D1%82%D0%B5%D0%B2%D0%BE%D0%B9_%D0%BC%D0%BE%D1%81%D1%82
# https://www.altlinux.org/PostgreSQL#%D0%A3%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0_%D0%B8_%D0%BD%D0%B0%D1%87%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%B7%D0%B0%D0%BF%D1%83%D1%81%D0%BA
# https://www.tecmint.com/install-postgresql-and-pgadmin-in-ubuntu/
# https://o7planning.org/11353/install-pgadmin-on-ubuntu
# https://redos.red-soft.ru/base/server-configuring/dbms/install-postgresql/?sphrase_id=53348
# https://redos.red-soft.ru/base/server-configuring/dbms/pgadmin4/
Task:
В компьютерном классе по 20 компьютеров и в каждом надо было установить Microsoft Office.
Для этого я написал скрипты инсталлятор и конфигуратор, которые позволяют мне выбрать дистрибутив, в котором я установливаю, саму программу для установки и настройки (не только офис).
# Разработка скрипта Автоматизация установки и настройки ПО.
Decision:
[root@hvredos ~]# ./InstallerOffice.sh
Do you want to install the program? (y/n) y
Select the distribution where you want to install the program (Centos 9 - 1 / Ubuntu 22.04 - 2 / Redos 7.3 - 3): 1
Select a program (Test - 0 / Sublime Text - 1 / Postgresql - 2 / PgAdmin - 3 / Git - 4 / Kvm - 5 / nfts-3g - 6 / libreoffice - 7): 0
Do you want to install the program? (y/n) y
Select the distribution where you want to install the program (Centos 9 - 1 / Ubuntu 22.04 - 2 / Redos 7.3 - 3): 2
Select a program (Test - 0 / Net-Tools - 1 / Ssh - 2): 0
[root@hvredos ~]# ./ConfigOffice.sh
Do you want to configure the program? (y/n) y
Select the distribution where you want to configure the program (Redhat - 1 / Debian - 2): 1
Select a program (Test - 0 / Disabling Lamp - 1 / Starting Lamp - 2 / Add users in postgressql - 3 / Moving linux folders to another disk - 4): 0
Do you want to configure the program? (y/n) n
Source:
# https://stackoverflow.com/questions/226703/how-do-i-prompt-for-yes-no-cancel-input-in-a-linux-shell-script
Task:
Столкнулся с такой проблемой, что маленький неттоп флешки не читает, он не был добавлен в домен и антивирус на нем не стоял.
Убедимся на другой машине, в моем случае ноутбуке, что флешка спокойно видит на нем файлы.
То есть это чистая флешка, не зараженная, и попробуем ее вставить в тот проблемный неттоп.
Тут мы увидим, что во флешке другая информация будет.
Как будто в самой флешке отображается сама флешка, и если ее открыть (что делать не стоит) тот там и будут наши файлы.
на самом деле они будут зашифрованны и флешка заражена.
# Разработка скрипта Восстановление флешки.
Decision:
- антивирус Касперский FREE - рекомендации по устранении проблм в компьютере - устранить - перезагрузиться -
- антивирус Касперский FREE - информация об устранении проблем
- вставить флешку - антвирус удалил какой-то файл (это и есть вирус)
- Открываем флешку после удаления вируса (пустой файл, хотя система показывает, что флешка заполнена, Он содержит зашифрованные файлы)
- восстановить зашифрованные файлы - Вставьте скрипт FlashDriveRecovery во флешку
Task:
Установка и настройка базы данных в PostgreSQL.
# Администрирование баз данных.
Decision:
root@hvalt:~# apt-get update
root@hvalt:~# apt-get install postgresql12-server
root@hvalt:~# /etc/init.d/postgresql initdb
root@hvalt:~# systemctl start postgresql
root@hvalt:~# systemctl enable postgresql
root@hvalt:~# pg_isready
root@hvalt:~# psql -U postgres
postgres=# CREATE USER tuser WITH PASSWORD 'tpassword';
postgres=# CREATE DATABASE tbase;
postgres=# GRANT ALL PRIVILEGES ON DATABASE tbase to tuser;
postgres=# psql -U postgres -c "\l+"
Список баз данных
Имя | Владелец | Кодировка | LC_COLLATE | LC_CTYPE | Права доступа | Размер | Табл. пространство | Опис
ание
-------------+----------+-----------+-------------+-------------+-----------------------+---------+--------------------+----------------------
----------------------
tbase | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =Tc/postgres +| 8041 kB | pg_default |
| | | | | postgres=CTc/postgres+| | |
| | | | | tuser=CTc/postgres | | |
postgres | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | | 8185 kB | pg_default | default administrativ
e connection database
...
postgres=# \c tbase
tbase=# GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO "tuser";
tbase=# ALTER DATABASE tbase OWNER TO tuser;
tbase=# \q
root@kvmubuntu:~# apt install postgresql postgresql-contrib
root@kvmubuntu:~# usermod -aG postgres tuser
root@kvmubuntu:~# sudo -i -u postgres
postgres@kvmubuntu:~$ psql
postgres=# \q
postgres@kvmubuntu:~$ createuser --interactive
Enter name of role to add: tuser
Shall the new role be a superuser? (y/n) y
postgres@kvmubuntu:~$ createdb tbase
postgres@kvmubuntu:~$ exit
root@kvmubuntu:~# psql -U tuser -d tbase
tbase=# \password
tbase=# GRANT ALL PRIVILEGES ON DATABASE tbase to tuser;
tbase=# GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO "tuser";
tbase=# ALTER DATABASE tbase OWNER TO tuser;
tbase=# GRANT pg_read_all_settings TO tuser;
tbase=# \conninfo
You are connected to database "tbase" as user "tuser" via socket in "/var/run/postgresql" at port "5432".
tbase=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
tbase | tuser | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/tuser +| 8561 kB | pg_default |
| | | | | tuser=CTc/tuser | | |
...
tbase=# SHOW config_file;
...
/etc/postgresql/14/main/postgresql.conf
tbase=# \q
root@kvmubuntu:~# vim /etc/postgresql/14/main/postgresql.conf
root@kvmubuntu:~# cat /etc/postgresql/14/main/postgresql.conf | grep listen_addresses
listen_addresses = 'tipubuntu' # what IP address(es) to listen on;
root@kvmubuntu:~# vim /etc/postgresql/14/main/pg_hba.conf
root@kvmubuntu:~# cat /etc/postgresql/14/main/pg_hba.conf
...
# "local" is for Unix domain socket connections only
host tbase tuser tipubuntu/32 md5
local all all peer
root@kvmubuntu:~# systemctl restart postgresql
tuser@kvmubuntu:~$ psql -U tuser -d tbase -h tipubuntu
tbase=# \d
Did not find any relations.
tbase=# \q
Source:
# https://www.digitalocean.com/community/tutorials/how-to-install-postgresql-on-ubuntu-22-04-quickstart - How To Install PostgreSQL on Ubuntu 22.04 [Quickstart].
# https://uchet-jkh.ru/i/kak-izmenit-parol-k-baze-dannyx-postgresql/ - Измените пароль для выбранного пользователя.
# https://asvignesh.in/how-to-get-the-postgresql-conf-file-location/ - Grant Role to the non-default user.
# https://postgrespro.ru/docs/postgresql/9.5/manage-ag-createdb - Создание базы данных.
Task:
Сделаем так, чтобы с клиентской машины Redos мы могли подключаться к серверу AltLinux удаленно.
# Администрирование базы данных.
Decision:
root@hvalt:~# su - postgres -c "psql -c 'SHOW config_file;'"
config_file
-------------------------------------
/var/lib/pgsql/data/postgresql.conf
(1 строка)
# echo "listen_addresses = 'IpAddr3, IpAddr2, hvalt'" >> /var/lib/pgsql/data/postgresql.conf
[root@hvredos ~]# cat /var/lib/pgsql/data/pg_hba.conf
...
# "local" is for Unix domain socket connections only
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
...
[root@hvredos ~]# vim /var/lib/pgsql/data/pg_hba.conf
[root@hvredos ~]# cat /var/lib/pgsql/data/pg_hba.conf | grep '10.38.'
# "local" is for Unix domain socket connections only
local all all trust
# IPv4 local connections:
host tbase tuser IpAddr2/21 md5
host all all 127.0.0.1/32 trust
root@hvalt:~# systemctl restart postgresql
root@hvalt:~# systemctl status postgresql
[root@hvredos ~]# psql -d tbase -U tuser -h hvalt
Task:
Для работы с базой в графическом интерфейсе установим Pgadmin.
# Администрирование базы данных.
Decision:
root@hvalt:~# apt-get install pgadmin3
root@hvalt:~# pgadmin3 &
- add server - name - tuser - host - hvalt- password - tpassword - ok
[root@hvredos ~]# dnf install postgresql-server
root@hvalt:~# postgresql-setup initdb
root@hvalt:~# systemctl enable postgresql
root@hvalt:~# systemctl start postgresql
root@hvalt:~# pg_isready
[root@hvredos ~]# psql -d tbase -U tuser -h hvalt
tbase=> \du
Список ролей
Имя роли | Атрибуты | Член ролей
----------+-------------------------------------------------------------------------+------------
tuser | | {}
postgres | Суперпользователь, Создаёт роли, Создаёт БД, Репликация, Пропускать RLS | {}
[root@hvredos ~]# dnf install pgadmin4 pgadmin4-qt
[root@hvredos ~]# pgadmin4-qt &
- root's password - add server - name - tuser - host - hvalt- password - tpassword - ok
Task:
Разработать схему базы данных Инвентаризация.
# Написание Sql запросов.
Decision:
Task:
Создать таблицы.
- В первой таблице отметим в каких зданиях находятся кабинеты.
- Вторая таблица отвечает за названия оборудований.
- Третья таблица отвечает за инвентарные номера оборудований, кабинетов и даты изменения.
# Разработка Sql таблиц Инвентаризация техники.
Decision:
tbase=> SELECT * FROM offices;
+====+========+===============+
| id | office | building |
+====+========+===============+
| 1 | 1 | Улица1 |
+----+--------+---------------+
| 2 | 2 | Улица1 |
+----+--------+---------------+
...
+----+--------+---------------+
| 8 | 8 | Улица2 |
+----+--------+---------------+
| 9 | 9 | Улица2 |
+----+--------+---------------+
tbase=> SELECT * FROM devices;
+====+=================================================+======================================+
| id | device | title |
+====+=================================================+======================================+
| 1 | Atc | Panasonic kx-tda100ru |
+----+-------------------------------------------------+--------------------------------------+
| 2 | Bидеокамера белая | (null) |
+----+-------------------------------------------------+--------------------------------------+
...
+----+-------------------------------------------------+--------------------------------------+
| 39 | Усилитель мощности | Eurosound xz-400 |
+----+-------------------------------------------------+--------------------------------------+
| 40 | 8 port video splitter | (null) |
+----+-------------------------------------------------+--------------------------------------+
tbase=> SELECT * FROM inventories;
+====+=============+===========+===========+==========+=====================+
| id | inventory | device_id | office_id | quantity | date |
+====+=============+===========+===========+==========+=====================+
| 1 | 457 | 1 | 1 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
| 2 | (null) | 2 | 1 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
...
+----+-------------+-----------+-----------+----------+---------------------+
| 67 | 556 | 33 | 9 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
| 68 | 426 | 32 | 9 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
Task:
Мне нужно вывести информацию, где в первом столбце будет инвентарные номера, во втором столбце, устройство и его название, а в третьем столбце вывести кабинеты, где находятся те самые оборудования
# Написание Sql запросов.
Decision:
tbase=> SELECT inventory, device, title, office
FROM inventories
INNER JOIN devices
ON inventories.device_id = devices.id
INNER JOIN offices
ON inventories.office_id = offices.id
WHERE office_id='6';
+=============+=========================+=================+========+
| inventory | device | title | office |
+=============+=========================+=================+========+
| 008 | Колонки | Sven sps-605 | 6 |
+-------------+-------------------------+-----------------+--------+
| 707 | Мультимедийный проектор | Epson eb-965h | 6 |
+-------------+-------------------------+-----------------+--------+
| 750 | Компьютер | Nuc mini pc kit | 6 |
+-------------+-------------------------+-----------------+--------+
Task:
Заметил ошибку в таблице, есть лишнее оборудование в кабинете. его на самом деле нету в кабинете и значит не должно быть в таблице.
# Написание Sql запросов.
Decision:
tbase=> DELETE FROM inventories
WHERE id='64';
SELECT inventory, device, title, office
FROM inventories
INNER JOIN devices
ON inventories.device_id = devices.id
INNER JOIN offices
ON inventories.office_id = offices.id
WHERE office_id='6';
+===========+=========================+=================+========+
| inventory | device | title | office |
+===========+=========================+=================+========+
| 707 | Мультимедийный проектор | Epson eb-965h | 6 |
+-----------+-------------------------+-----------------+--------+
| 750 | Компьютер | Nuc mini pc kit | 6 |
+-----------+-------------------------+-----------------+--------+
tbase=> SELECT * FROM inventories;
+====+=============+===========+===========+==========+=====================+
| id | inventory | device_id | office_id | quantity | date |
+====+=============+===========+===========+==========+=====================+
| 1 | 457 | 1 | 1 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
| 2 | (null) | 2 | 1 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
...
+----+-------------+-----------+-----------+----------+---------------------+
| 67 | 556 | 33 | 9 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
| 68 | 426 | 32 | 9 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
Task:
Появилось новое обрудование, и нужно его внести в таблицу.
# Написание Sql запросов.
Decision:
tbase=> INSERT INTO inventories (inventory, device_id, office_id, quantity, date)
VALUES ('testinv1', '39', '1', '1', '2017-12-12 12:12:12');
tbase=> SELECT * FROM inventories;
+====+=============+===========+===========+==========+=====================+
| id | inventory | device_id | office_id | quantity | date |
+====+=============+===========+===========+==========+=====================+
| 1 | 457 | 1 | 1 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
| 2 | (null) | 2 | 1 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
...
+----+-------------+-----------+-----------+----------+---------------------+
| 68 | 426 | 32 | 9 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
| 69 | testinv1 | 39 | 1 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
Task:
в предыдущей задаче не верные данные внес в таблицу, нужно подкорректировать.
# Написание Sql запросов.
Decision:
tbase=> UPDATE inventories
SET inventory='testinv2', office_id='9'
WHERE id='69';
tbase=> SELECT * FROM inventories;
+====+=============+===========+===========+==========+=====================+
| id | inventory | device_id | office_id | quantity | date |
+====+=============+===========+===========+==========+=====================+
| 1 | 457 | 1 | 1 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
| 2 | (null) | 2 | 1 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
...
+----+-------------+-----------+-----------+----------+---------------------+
| 68 | 426 | 32 | 9 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
| 69 | testinv2 | 39 | 9 | 1 | 2017-12-12 12:12:12 |
+----+-------------+-----------+-----------+----------+---------------------+
tbase=> SELECT inventory, device, title, office
FROM inventories
INNER JOIN devices
ON inventories.device_id = devices.id
INNER JOIN offices
ON inventories.office_id = offices.id
WHERE office_id='9';
+=============+==========================+==================+========+
| inventory | device | title | office |
+=============+==========================+==================+========+
| 650 | Компьютер | Nuc | 9 |
+-------------+--------------------------+------------------+--------+
| 426 | Интерактиная доска | 80 | 9 |
+-------------+--------------------------+------------------+--------+
| 556 | Короткофокусный проектор | Benq | 9 |
+-------------+--------------------------+------------------+--------+
| 010 | Колонки | Microlab solo 1 | 9 |
+-------------+--------------------------+------------------+--------+
| testinv2 | Усилитель мощности | Eurosound xz-400 | 9 |
+-------------+--------------------------+------------------+--------+
2019-11-01 - 2021-05-30: Easy School, Иркутск. Должность: English Level Elementary A - Дополнительное образование. Достижения: Разработал программу телеграмм бот Переводчик. Дополнительная информация: Навыки - English, Python, Clouds.
Show more
Services:
# Разработка функции меню.
# Администрирование локальных серверов.
# Разработка переводчик.
# Администрирование баз данных.
# Разработка базы данных Словарь.
# Написание Sql запросов.
Task:
написать консольное меню, которая будет предлагать какие действя нужно выполнить
# Разработка Функции меню.
Decision:
root@kvmubuntu:~# python3 pyMenu.py
Привет!
Я тестовый бот.
Выбери программу, которую ты хочешь выполнить
(0, translator, dictionary): translator
Что именно нужно сделать
(translate, back): translate
Здесь программа переведет вам текст
Что именно нужно сделать
(translate, back): back
Вы вернулись в главное меню
Привет!
Я тестовый бот.
Выбери программу, которую ты хочешь выполнить
(0, translator, dictionary): dictionary
Что именно нужно сделать
(list,term,back): list
Вывести список слов
Что именно нужно сделать
(list,term,back): term
Выбрать слово их списка
Что именно нужно сделать
(list,term,back): back
Вы вернулись в главное меню
Привет!
Я тестовый бот.
Выбери программу, которую ты хочешь выполнить
(0, translator, dictionary): 0
translator
Task:
Подготовка библиотек.
# Администрирование локальных серверов.
Decision:
root@kvmubuntu:~# python3 -m venv tenv
root@kvmubuntu:~# source tenv/bin/activate
(tenv) root@kvmubuntu:~# pip install -r requirements.txt
Task:
Раработка программы переводчик.
Добавить переводчик в функцию.
# Разработка переводчик.
Decision:
(tenv) root@kvmubuntu:~# python3 translator.py
Hi, how are you?
(tenv) root@kvmubuntu:~# python3 pyTranslator1.py
Введите текст, который вы хотите перевести: Вчера я забронировал у вас номер в отеле.
Tom booked a room at the hotel
(tenv) root@kvmubuntu:~# python3 pyTranslator2.py
Введите текст, который вы хотите перевести: Вчера я забронировал у вас номер в отеле.
Yesterday I booked a hotel room with you.
(tenv) root@kvmubuntu:~# python3 pyTranslator3.py
Введите текст, который вы хотите перевести: Для тестирования работоспособности телеграм бота переводчик, написанном на Python мы использовали готовый преднастроенный телеграм бот сервер.
To test the functionality of the telegram bot translator, written in Python, we used a ready-made pre-configured telegram bot server.
(tenv) root@kvmubuntu:~# python3 pyTranslator3.py
Введите текст, который вы хотите перевести: To test the functionality of the telegram bot translator, written in Python, we used a ready-made pre-configured telegram bot server.
Для проверки работоспособности переводчика телеграмм-бота, написанного на Python, мы использовали готовый, предварительно настроенный сервер телеграм-бота.
(tenv) root@kvmubuntu:~# python3 pyTranslator3.py
Введите текст, который вы хотите перевести: ;
Я тебя не понимаю
Task:
Применение библиотеки Translator и готовой функции меню.
# Разработка переводчик.
Decision:
(tenv) root@kvmubuntu:~# python3 pyMenuTranslator.py
Привет!
Я тестовый бот.
Выбери программу, которую ты хочешь выполнить
(0, translator, dictionary): translator
Что именно нужно сделать
(translate, back): translate
Введите текст, который вы хотите перевести: Привет. Как дела?
Hi, how are you?
Что именно нужно сделать
(translate, back): back
Вы вернулись в главное меню
Привет!
Я тестовый бот.
Выбери программу, которую ты хочешь выполнить
(0, translator, dictionary): 0
translator
Task:
Установка и настройка базы данных в PostgreSQL.
# Администрирование базы данных.
Decision:
(tenv) root@kvmubuntu:~# createdb tbase2
(tenv) root@kvmubuntu:~# psql -U tuser -d tbase -h tipubuntu
tbase=# GRANT ALL PRIVILEGES ON DATABASE tbase2 to tuser;
tbase=# ALTER DATABASE tbase2 OWNER TO tuser;
tbase=# \l+
tbase | tuser | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/tuser +| 9801 kB | pg_default |
| | | | | tuser=CTc/tuser | | |
tbase2 | tuser | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/tuser +| 8577 kB | pg_default |
| | | | | tuser=CTc/tuser | | |
root@kvmubuntu:~# vim /etc/postgresql/14/main/pg_hba.conf
root@kvmubuntu:~# cat /etc/postgresql/14/main/pg_hba.conf
...
host tbase2 tuser tipubuntu1/24 md5
root@kvmubuntu:~# systemctl restart postgresql
Source:
# https://postgrespro.ru/docs/postgresql/9.5/manage-ag-createdb - Создание базы данных.
Task:
Разработать схему БД Словарь.
# Разработка базы данных Словарь.
Decision:
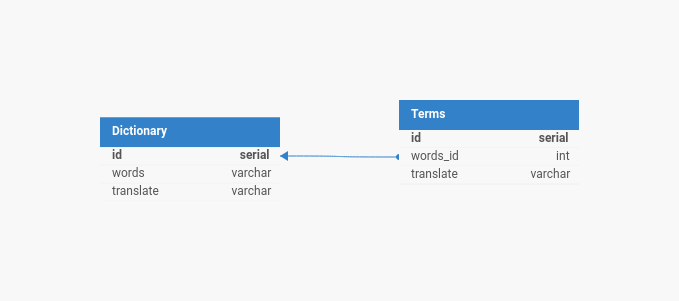
Task:
Разработка базы данных.
Словарь
id | words | translate
1 | Текст1 | Text1
2 | Текст2 | Text2
3 | Текст3 | Text3
Термины
id | words_id | description | translate
1 | 1 | Текст4 | Text4
2 | 3 | Текст5 | Text5
# Разработка базы данных Словарь.
Decision:
(tenv) root@kvmubuntu:~# psql -U tuser -d tbase2 -h tipubuntu
tbase2=# CREATE TABLE tbase2 (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
words VARCHAR(1000),
translate VARCHAR(1000)
);
tbase2=# CREATE TABLE Terms (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
words_id INT,
description VARCHAR(1000),
translate VARCHAR(1000),
CONSTRAINT fk_tbase2
FOREIGN KEY(words_id)
REFERENCES tbase2(id)
);
tbase2=# INSERT INTO tbase2 (words, translate)
VALUES ('Текст1', 'Text1'), ('Текст2', 'Text2'), ('Текст3', 'Text3');
tbase2=# INSERT INTO Terms (words_id, description, translate)
VALUES (1, 'Текст4', 'Text4'), (3, 'Текст5','Text5');
Task:
Написать запрос
words | translate | description | translate
Текст1 | Text1 | Текст4 | Text4
Текст3 | Text3 | Текст5 | Text5
# Написание Sql запросов.
Decision:
tbase2=# select words, dictionary.translate, description, Terms.translate
from dictionary
inner join Terms
on dictionary.id = Terms.words_id;
words | translate | description | translate
--------+-----------+-------------+-----------
Текст1 | Text1 | Текст4 | Text4
Текст3 | Text3 | Текст5 | Text5
(2 rows)
Source:
# https://proglib.io/p/rukovodstvo-po-sql-dlya-nachinayushchih-chast-1-sozdanie-bazy-dannyh-tablic-i-ustanovka-svyazey-mezhdu-tablicami-2022-02-07 - Руководство по SQL для начинающих. Часть 1: создание базы данных, таблиц и установка связей между таблицами.
# https://sql-academy.org/ru/guide/inner-join - Внутреннее соединение INNER JOIN.
Task:
Миграция базы с одного сервера на другой.
# Администрирование базы данных.
Decision:
(tenv) root@kvmubuntu:~# pg_dump -Fc -v --username=tuser --dbname=tbase2 -f datapsql2.dump
root@aw:/# scp datapsql2.dump tuser@tipubuntu:/home/tuser/
(tenv) root@kvmubuntu:~# pg_restore -v --no-owner --port=5432 --username=tuser --dbname=tbase2 datapsql2.dump
Source:
# https://www.youtube.com/@shcoder001 - Переводчик бот в telegram на python за 5 минут aiogram.
Task:
Применение библиотеки psycopg2.
# Разработка Переводчик.
Decision:
(tenv) root@kvmubuntu:~# python3 pyPsql.py
('Внутреннее соединение', 'Inner join', 'Возвращаются только те строки, где ключевые значения совпадают в обеих таблицах', 'Only those rows are returned where the key values match in both tables')
('Полное соединение', 'Cross Join', 'Позволяет получить декартово произведение нескольких таблиц. особенно полезен, когда между таблицами нет определенной связи, и вам нужно создать полную комбинацию записей из каждой таблицы', '-')
('Декартово произведение', 'Cartesian product', 'Результат соединения строки из первой таблицы с каждой строкой из второй таблицы', '-')
(tenv) root@kvmubuntu:~# python3 pyPsql.py
('Внутреннее соединение', 'Inner join', 'Возвращаются только те строки, где ключевые значения совпадают в обеих таблицах', 'Only those rows are returned where the key values match in both tables')
('Полное соединение', 'Cross Join', 'Позволяет получить декартово произведение нескольких таблиц. особенно полезен, когда между таблицами нет определенной связи, и вам нужно создать полную комбинацию записей из каждой таблицы', '-')
('Декартово произведение', 'Cartesian product', 'Результат соединения строки из первой таблицы с каждой строкой из второй таблицы', '-')
Source:
# https://ru.hexlet.io/blog/posts/python-postgresql - Использование Psycopg2.
# https://khashtamov.com/ru/postgresql-python-psycopg2/ - Начало работы.
Task:
Применение библиотеки Telebot.
# Разработка Переводчик.
Decision:
(tenv) root@kvmubuntu:~# python3 pyTranslatorMenuTelebot.py
- /Start
- Привет, David! Я тестовый бот.
Выбери программу, которую ты хочешь выполнить:
1. Чем полезен данный бот
2. Функции бота (что может данный бот)
3. Для тех кто хочет поддержать нас и наш проект
- Функции бота
- Добро пожаловать главное меню бота
В скором будущем мы будем добавлять сюда новые функции!
1. Переводчик
2. Словарь
- Переводчик
- Напишите сообщения, а я переведу его
- Привет, Катя!
- Hello, Katya!
- Переводчик
- Напишите сообщения, а я переведу его
- Dear Kate!
- Дорогая Кейт!
Source:
# https://www.w3schools.com/python/ref_func_input.asp - Python input() Function.
# https://proglib.io/p/samouchitel-po-python-dlya-nachinayushchih-chast-10-uslovnyy-cikl-while-2022-12-22 - Управление бесконечным циклом while в Питоне.
# https://letpy.com/python-guide/functions/ - Функции в Python для начинающих.
# https://ru.stackoverflow.com/questions/1211592/%D0%9A%D0%B0%D0%BA-%D1%81%D0%BE%D0%B7%D0%B4%D0%B0%D1%82%D1%8C-%D0%BC%D0%B5%D0%BD%D1%8E-%D1%81-%D0%B2%D1%8B%D0%B1%D0%BE%D1%80%D0%BE%D0%BC-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%B9-%D0%BD%D0%B0-python - Как создать меню с выбором функций на Python?
# https://ru.stackoverflow.com/questions/1341916/%D0%9A%D0%B0%D0%BA-%D0%B7%D0%B0%D1%86%D0%B8%D0%BA%D0%BB%D0%B8%D1%82%D1%8C-%D0%BC%D0%B5%D0%BD%D1%8E-%D0%B8%D0%BC%D0%B5%D1%8E%D1%89%D0%B5%D0%B5-%D0%BF%D0%BE%D0%B4%D0%BC%D0%B5%D0%BD%D1%8E-%D0%B2-python - Как зациклить меню, имеющее подменю в python?
# https://docs.python.org/3/tutorial/venv.html - Creating Virtual Environments.
# https://www.youtube.com/watch?v=A1p7bEtTlxc&t=4s - Как сделать меню для Телеграм Бота на Python.
Task:
Добавить информацию в базу данных в телеграм бот.
# Разработка Переводчик.
Decision:
(tenv) root@kvmubuntu:~# psql -U tuser -d tbase2 -h tipubuntu
tbase2=# select * from Dictionary;
id | words | translate
----+------------------------+-------------------
1 | Внутреннее соединение | Inner join
2 | Доступ | Available
3 | Полное соединение | Cross Join
4 | Декартово произведение | Cartesian product
5 | Текст4 | Text4
(5 rows)
(tenv) root@kvmubuntu:~# vim .env
(tenv) root@kvmubuntu:~# cat .env
TOKEN='tkey'
DB_URL='postgres://tuser:tpassword@tipubuntu:5432/tbase2'
Decision:
(tenv) root@kvmubuntu:~# python3 py.py
- Чем полезен бот ?
- Функции бота:
1. Переводчик
2. Дополнить словарь
- Дополнить словарь
- Напишите 2 сообщения (предложение и его перевод), которые нужно добавить в словарь:
- new
новый
- Info added to the dictionary.
- Словарь
- Вывожу словарь:
| Inner join | Возвращаются только те строки, где ключевые значения совпадают в обеих таблицах | Only those rows are returned where the key values match in both tables |
| Cross Join | Позволяет получить декартово произведение нескольких таблиц. особенно полезен, когда между таблицами нет определенной связи, и вам нужно создать полную комбинацию записей из каждой таблицы | - |
| Cartesian product | Результат соединения строки из первой таблицы с каждой строкой из второй таблицы | - |
Selected to the dictionary.
(tenv) root@kvmubuntu:~# psql -U tuser -d tbase2 -h tipubuntu
tbase2=# select * from Dictionary;
...
49 | new | новый
tbase2=# TRUNCATE Terms, Dictionary CASCADE;
Source:
# https://stackoverflow.com/questions/75900203/how-do-i-connect-my-telegram-bot-telebot-to-postgresql-url - How do I connect my telegram bot (telebot) to PostgreSQL url.
# https://pythonru.com/osnovy/globalnye-peremennye-python - Правила использования global.
# https://ru.stackoverflow.com/questions/1103332/Авторизация-в-телеграмм-боте-на-python - Авторизация в телеграмм боте на Python.
# https://otvet.mail.ru/question/219454196 - Python. Telegram bot api Как из Username получить user_id.
# https://stackoverflow.com/questions/13223820/postgresql-delete-all-content - PostgreSQL удаляет все содержимое.
Task:
Настройка службы бота.
# Администрирование локальных серверов.
Decision:
root@kvmubuntu:~# vim /etc/systemd/system/dato38itbot.service
root@kvmubuntu:~# cat /etc/systemd/system/dato38itbot.service
[Unit]
Description=Telegram dato38it-bot
After=network.target
[Service]
User=tuser
Group=tuser
WorkingDirectory=/home/tuser/dato38itbot/
VIRTUAL_ENV=/home/tuser/dato38itbot/telegaenv
Environment=PATH=$VIRTUAL_ENV/bin:$PATH
ExecStart=/home/tuser/dato38itbot/telegaenv/bin/python /home/tuser/dato38itbot/main.py
Restart=on-failure
[Install]
WantedBy=multi-user.target
root@kvmubuntu:~# systemctl daemon-reload
root@kvmubuntu:~# systemctl enable dato38itbot.service
root@kvmubuntu:~# systemctl start dato38itbot.service
root@kvmubuntu:~# systemctl status dato38itbot.service
Source:
# https://thecode.media/systemctl/ - Готовим файл для работы службы.
# https://synay.net/vps/preconfigured/own-telegram-bot-server-debian-12 - Создадим файл службы, чтобы запускать бот автоматически.
# https://gist.github.com/ricferr/90583f608f0b0ae9c3cf6833be04ab85 - How to create a systemd service for python script with virtualenv.
2018-03-01 - 2022-11-01: Всероссийский государственный университет юстиции, Иркутск. Должность: Технический специалист. Достижения: Разработал программу Обработка и сортировка Html-кода с целью упрощения корректировки тегов на сайте организации по запросам от руководства Дополнительная информация: работа с сайтами, поддержка функционирования серверов и сервисов СУБД, техническая поддержка пользователей
Show more
Services:
# Разработка Парсинг данных в файлах.
# Разработка скрипта Парсинг документов на сайте.
Task:
В файле input.txt надо обычный текст преобразовать в html код формат, добавив только необходимые тэги, и записать результат в output.html.
# Разработка Парсинг данных в файлах.
Decision:
INFORMATION WILL BE ADDED SOON!
Source:
# https://pythonworld.ru/tipy-dannyx-v-python/fajly-rabota-s-fajlami.html - Чтение из файла.
# https://docs-python.ru/tutorial/chtenie-zapis-fajl/odnovremennoe-chtenie-zapis-raznye-fajly/ - Работа с несколькими файлами в Python.
# https://sky.pro/media/chtenie-fajla-postrochno-v-spisok-na-python/ - Использование встроенной функции open().
# https://sky.pro/media/chtenie-fajla-postrochno-v-spisok-na-python/?ysclid=lv9i6ky8w2363195830 - Использование генераторов.
# https://translated.turbopages.org/proxy_u/en-ru.ru.8446d21d-66250fbc-1552d51e-74722d776562/https/stackoverflow.com/questions/54785152/replace-tab-with-space-in-entire-text-file-python?__ya_mt_enable_static_translations=1 - Заменить табуляцию пробелом во всем текстовом файле python.
# https://pythonturbo.ru/kak-v-python-dobavit-tekst-v-fajl/ - Добавление текста в файл с помощью оператора with
Task:
На странице https://tdomain.ru/sveden/education под поле "Образовательная программа, направленность, профиль, шифр и наименование научной специальности" в таблице "Образование" (информация по образовательным программам) необходимо добавить тег itemprop="eduProf". В данной таблице тег <tr itemprop="eduOp">, который нужно заменить на <tr itemprop="eduOprog">.
# Разработка скрипта Парсинг сайта.
Decision:
INFORMATION WILL BE ADDED SOON!
ШАГИ ВЫПОЛНЕНИЯ:
1. Прорамма будет апрашивать страницу для парсинга.
2. Парсинг страницы сайта по тегам
3. Поиск тега который нужно аменить
4. амена тега
5. Публикация именения на сайт
Task:
Написать скрипт, который проверяет все страницы сайта на отсутствие pdf файлов больше 15 Мб.
# Разработка скрипта Парсинг документов на сайте.
Decision:
root@kvmubuntu:~# wget --no-check-certificate -r -l 1 -A pdf https://tdomain.ru/sveden/document
root@kvmubuntu:~# chmod +x FileWeight.sh
root@kvmubuntu:~# ./FileWeight.sh
Enter a link to the site: https://tdomain.ru/sveden/document
Come up with a name for the directory where the files will be written: tdir
/home/tuser/tdir create
...
root@kvmubuntu:~# cat /home/tuser/tdir/output
/home/tuser/tdir/tdomain.ru/Media/irk/Документы института/2018/tDoc1.pdf
root@kvmubuntu:~# ls -l /home/tuser/tdir/tdomain.ru/Media/irk/Документы\ института/2018/tDoc1.pdf
-rw-r--r--. 1 tuser tuser 20055320 июн 30 2018 '/home/tuser/tdir/tdomain.ru/Media/irk/Документы института/2018/tDoc1.pdf'
Source:
# https://stackoverflow.com/questions/4846007/check-if-directory-exists-and-delete-in-one-command-unix
2022-11-01 - 2023-05-30: Сбер Университет, Иркутск. Должность: Инженер с большими данными - Дополнительное образование. Достижения: Для защиты проекта по теме "Разработка хранилища данных банка с выявлением случаев мошенничества" разработал корпоративное хранилища архивных данных из разных источников применительно к банковской деятельности. Дополнительная информация: None
Show more
Services:
# Разработка Парсинг данных из базы данных.
# Разработка Загрузка данных в хранилище и формирование отчетности.
# Администрирование локальных серверов.
Task:
Разработка ETL процесса, получающий ежедневную выгрузку данных (предоставляется за 3 дня), загружающий ее в хранилище данных и ежедневно строящий отчет.
Ежедневно некие информационные системы выгружают три следующих файла:
1. Список транзакций за текущий день. Формат – CSV.
2. Список терминалов полным срезом. Формат – XLSX.
3. Список паспортов, включенных в «черный список» - с накоплением с начала месяца. Формат – XLSX.
Сведения о картах, счетах и клиентах хранятся в СУБД PostgreSQL. Во вложении реквизиты для подключения.
Вам предоставляется выгрузка за последние три дня, ее надо обработать. В качестве хранилища выступает ваша учебная база (edu). Данные должны быть загружены в хранилище со следующей структурой (имена сущностей указаны по существу, без особенностей правил нейминга, указанных далее).
Типы данных в полях можно изменять на однородные если для этого есть необходимость. Имена полей менять нельзя. Ко всем таблицам SCD1 должны
быть добавлены технические поля create_dt, update_dt; ко всем таблицам SCD2 должны быть добавлены технические поля effective_from, effective_to, deleted_flg.
По результатам загрузки ежедневно необходимо строить витрину отчетности по мошенническим операциям. Витрина строится накоплением, каждый новый отчет укладывается в эту же таблицу с новым report_dt.
В витрине должны содержаться следующие поля:
1. event_dt - Время наступления события. Если событие наступило по результату нескольких действий – указывается время действия, по которому установлен факт мошенничества.
2. passport - Номер паспорта клиента, совершившего мошенническую операцию.
3. fio - ФИО клиента, совершившего мошенническую операцию.
4. phone - Номер телефона клиента, совершившего мошенническую операцию.
5. event_type - Описание типа мошенничества.
6. report_dt - Время построения отчета.
Признаки мошеннических операций:
1. Совершение операции при просроченном или заблокированном паспорте.
2. Совершение операции при недействующем договоре.
3. Совершение операций в разных городах в течение одного часа.
4. Попытка подбора суммы. В течение 20 минут проходит более 3х операций соследующим шаблоном – каждая последующая меньше предыдущей, при этом отклонены все кроме последней. Последняя операция (успешная) в такой цепочке считается мошеннической.
При именовании таблиц необходимо придерживаться следующих правил (для автоматизации проверки):
1. tuser.<CODE>_STG_<TABLE_NAME> - Таблицы для размещения стейджинговых таблиц (первоначальная загрузка), промежуточное выделение инкремента, если требуется. Временные таблицы, если такие потребуются в расчете, можно также складывать с таким именованием. Имя таблиц можете выбирать произвольное, но смысловое.
2. tuser.<CODE>_DWH_FACT_<TABLE_NAME> - Таблицы фактов, загруженных в хранилище. В качестве фактов выступают сами транзакции и «черный список» паспортов. Имя таблиц – как в ER диаграмме.
3. tuser.<CODE>_DWH_DIM_<TABLE_NAME> - Таблицы измерений, хранящиеся в формате SCD1. Имя таблиц – как в ER диаграмме.
4. tuser.<CODE>_DWH_DIM_<TABLE_NAME>_HIST - Таблицы измерений, хранящиеся в SCD2 формате (только для тех, кто выполняет усложненное задание). Имя таблиц – как в ER диаграмме.
5. tuser.<CODE>_REP_FRAUD - Таблица с отчетом.
6. tuser.<CODE>_META_<TABLE_NAME> - Таблицы для хранения метаданных. Имя таблиц можете выбирать произвольное, но
смысловое.
7. <CODE> - 4 буквы вашего персонального кода.
Выгружаемые файлы именуются согласно следующему шаблону:
1. transactions_DDMMYYYY.txt
2. passport_blacklist_DDMMYYYY.xlsx
3. terminals_DDMMYYYY.xlsx
Предполагается что в один день приходит по одному такому файлу. После загрузки соответствующего файла он должен быть переименован в файл с расширением .backup чтобы при следующем запуске файл не искался и перемещен в каталог archive:
1. transactions_DDMMYYYY.txt.backup
2. passport_blacklist_DDMMYYYY.xlsx.back
3. upterminals_DDMMYYYY.xlsx.backup
Желающие могут придумать, обосновать и реализовать более технологичные и учитывающие сбои способы обработки (за это будет повышен балл).
В classroom выкладывается zip-архив, содержащий следующие файлы и каталоги:
1. main.py - Файл, обязательный. Основной процесс обработки.
2. файлы с данными - Файл, обязательный. Те файлы, которые вы получили в качестве задания. Просто скопируйте все 9 файлов.
3. main.ddl - Файл, обязательный. Файл с SQL кодом для создания всех необходимых объектов в базе edu.
4. main.cron - Файл, обязательный. Файл для постановки вашего процесса на расписание, в формате crontab
5. archive - Каталог, обязательный. Пустой, сюда должны перемещаться отработанные файлы
6. sql_scripts - Каталог, необязательный. Если вы включаете в main.py какие-то SQL скрипты, вынесенные в отдельные файлы – помещайте их сюда.
7. py_scripts - Каталог, необязательный. Если вы включаете в main.py какие-то python скрипты, вынесенные в отдельные файлы – помещайте их сюда.
# Разработка Парсинг данных из базы данных.
Decision:
root@kvmubuntu:~# mkdir archive
root@kvmubuntu:~# vim snippet_pg.py
root@kvmubuntu:~# chmod +x snippet_pg.py
root@kvmubuntu:~# touch main.cron
root@kvmubuntu:~# vim SCD1_incremental_full_script.sql
root@kvmubuntu:~# wget https://drive.google.com/file/d/13WSK0C1Z36hhsopebgEv2bGLAoxEsLUp/view?usp=drive_web&authuser=0
root@kvmubuntu:~# unzip data.zip
Task:
Настроить python
# Администрирование локальных серверов.
Decision:
root@kvmubuntu:~# apt install python3.10-venv
root@kvmubuntu:~# python3.10 -m venv venv
root@kvmubuntu:~# source venv/bin/activate
root@kvmubuntu:~# pip install pandas
Task:
Создадите таблицы в базе (main.ddl).
Алгоритм для файла main.py: Подключитесь к двум базам, Очистите весь стейджинг. Загрузите файлы transactions_01032021.txt, terminals_01032021.xlsx, passport_blacklist_01032021.xlsx в стейджинг. Загрузите таблицы clients, accounts, cards в стейджинг. Используйте следующий подход: Выполните запрос к базе 1, Сохраните полученный результат в DataFrame, Загрузите DataFrame в базу 2. Загрузите данные из стейджинга в целевую таблицу xxxx_dwh_dim_terminals, xxxx_dwh_dim_cards, xxxx_dwh_dim_accounts, xxxx_dwh_dim_clients. Загрузите данные из стейджинга в целевую таблицу xxxx_dwh_fact_passport_blacklist, xxxx_dwh_fact_transactions.. Фактовые таблицы данные перекладываются «простым инсертом», то есть необходимо выполнить один INSERT INTO ... SELECT .... Напишите скрипт, соединяющий нужные таблицы для поиска операций, совершенных при недействующем договоре. Отладьте ваш скрипт для одной даты PgAdmin, он должен выдавать результат. Результат выполнения скрипта загружайте в таблицу xxxx_rep_fraud. Незабывайте сформировать поле report_dt. Зафиксируйте изменения. Отключитесь от баз. Переименуйте обработанные файлы и перенесите их в другой каталог. отладить его работоспособность навсех трех днях загрузки.
Заполните файл main.cron расписанием и командой исполнения вашего скрипта. Расписание установите так, как считаете нужным чтобы ваши данные заполнились корректно.
# Разработка Загрузка данных в хранилище и формирование отчетности.
Decision:
root@kvmubuntu:~# vim main.py
root@kvmubuntu:~# python3 main.py
root@kvmubuntu:~# ls archive/
passport_blacklist_01032021.xlsx.backup terminals_01032021.xlsx.backup transactions_01032021.txt.backup
root@kvmubuntu:~# psql -U tuser
tuser=# select * from tuser.XXXX_rep_fraud;
Decision:
По следующим признакам получилось выявить мошеннические транзакции: выполнение операции с просроченным или заблокированным паспортом, выполнение операции с недействительным контрактом, выполнение операций в разных городах в течение одного часа
Source:
# https://dzen.ru/a/Ypr65Wh4jmLimA3o
# https://www.youtube.com/watch?v=Je3Y8up0Qbs&list=LL&index=5&t=98s
# https://losst.pro/kak-posmotret-otkrytye-porty-v-linux?ysclid=lpe5qjsv9o445640330
# https://www.pgadmin.org/download/pgadmin-4-apt/
# https://losst.pro/spisok-kontejnerov-docker
2011-09-01 - 2018-05-30: Иркутский государственный университет, Иркутск. Должность: Информационные технологии и телекоммуникационные системы - Бакалавр / Электроника и наноэлектроника - Магистр / Информационная безопасность - Дополнительное образование. Достижения: Защитил магистерскую диссертацию по теме "Использование данных одночастотных приемников Спутниковых Радионавигационных Систем для коррекции модели ионосферы" и для защиты магистерской диссертации разработал программу "Обработка и сортировка данных в файлах Rinex формата" Дополнительная информация: None
Show more
Services:
# Излучение и распространение радиоволн.
# Разработка Парсинг данных в файлах.
Task:
Методика коррекции ионосферы по данному приёмнику СРНС.
# Излучение и распространение радиоволн.
Decision:
Рассмотрим возможность оценки вклада ионосферы в измерения псевдодальности (ПД) с помощью одночастотного приёмника ГЛОНАСС/GPS. Для этого будем считать, что координаты приемника x, y, z неизменны и известны с высокой точностью. ПД от i-го навигационного спутника (НС) с координатами xi, yi, zi определим как измеренную в свободном пространстве дальность D'i=сτ'i, отличающуюся от геометрической дальности (ГД) Di на неизвестную величину ρ:

D'i=сτ'i определяется по разности моментов приема и передачи навигационного сигнала между временными шкалами НС и приемника. Если точность шкалы НС с учетом её коррекции достаточна для определения момента излучения, то из-за нестабильности шкалы приемника необходимо учитывать её мгновенный сдвиг относительно шкалы НС на неизвестную величину t' и ρ=ct'. В многоканальных одночастотных приемниках t' не зависит от i и значение ρ одинаково для всех НС в данный момент времени [6].
В реальных условиях результаты измерения ПД D''i отличаются от значения D'i из формулы (4.1) из-за влияния различных факторов на распространение навигационных сигналов. Основные ошибки, возникающие при этом, вызваны запаздыванием сигнала в ионосфере и тропосфере , а также погрешностями определения эфемерид . Другие ошибки хорошо компенсируются алгоритмами обработки сигналов. Например, влияние многолучевости значительно уменьшается усреднением данных на интервале 30 с и более, а релятивистские эффекты устраняются коррекцией навигационного сигнала [6].
Таким образом, ошибка измерения ПД в основном определяется следующими составляющими:

Отсюда можно найти вклад ионосферы в ошибку измерения ПД для i-го НС:
Величина ρ в формуле (4.3) зависит от расхождения шкал времени НС и приемника и меняется в очень широких пределах.
При решении навигационной задачи относительно времени, шкала приемника может быть привязана к шкале НС, но найденная при этом величина ρ' будет характеризовать эффективное значение с учетом других ошибок определения ПД, и в этом случае будет иметь смысл отклонения от некоторого среднего значения для всех НС, участвующих в навигационном решении [6].
Для устранения влияния нестабильности временнόй шкалы приемника построим разность ошибок ионосферы для i-го и j-го НС в один момент времени:
Как видно, точность определения зависит от погрешностей определения эфемерид выбранных НС и разностей тропосферных задержек сигналов от них. обычно составляет единицы метров. Если из созвездия выбирать НС со «свежими» эфемеридами, то эта погрешность уменьшится до ~1 м. Применение постобработки и использование уточнённых эфемерид дает погрешность значительно меньше 1 м. Если предположить, что ошибки для двух НС независимы, а их величины примерно одинаковы, то общая ошибка из-за погрешностей задания эфемерид [6]:
Задержка в тропосфере приводит к ошибке в измерении ПД, которая хорошо компенсируется простыми моделями тропосферы. В нормальных условиях в тропосфере для углов места β > 5º и достижения погрешности после коррекции < 0.5 м можно воспользоваться формулой:
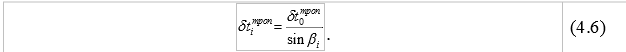
Здесь - задержка сигнала в тропосфере для зенитных НС, равная ~7 нс, что соответствует пути 2.1 м. Для увеличения точности коррекции можно применить модель Саастамойнена.
Таким образом, общая величина ошибки определения в благоприятных условиях составляет ~1÷2 м и вариации ионосферной задержки величиной ~10 и более метров могут быть определены одночастотным приемником ГНСС.
Task:
Получение данных с одночастотного приемника СРНС.
# Спутниковые радионаввигационные системы.
Decision:
Для проверки способа определения вариации ионосферной задержки 19 мая 2015 года провел обработку данных измерения навигационных сигналов от нескольких НС. Для измерений использовался 20 канальный одночастотный приемник BU-353 фирмы GlobalSat. Этот приемник предназначен для ГНСС GPS, работает на частоте L1 по C/A коду и имеет высокую чувствительность 159 дБм. Данные о псевдодальностях доступны только при использовании бинарного протокола, поэтому при наблюдениях применялась программа SirfTech версии 2.20 и данные записывались в RINEX файл. Описание программы SirfTech можно увидеть прил. 5.
Task:
Алгоритм обработки данных.
# Спутниковые радионаввигационные системы.
Decision:
Большая часть программного обеспечения обработки данных GPS использует определенный набор наблюдений:
- фазовые измерения на одной или двух несущих частотах;
- измерения псевдодальности (кода), которые соответствуют разности между временем получения и временем передачи отдельных сигналов спутника;
- время наблюдения считывается с часов приемника в момент измерения фазы несущей и/или кода.
При обработке необходимыми являются: фаза, код и время, определение которых дано выше, и некоторая информация относительно станции, такая как название станции, высота антенны и другие [5].
Task:
Описание формата RINEX.
# Спутниковые радионаввигационные системы.
Decision:
Для решении навигационной задачи исходными данными являются файлы в формате RINEX - независимый от приемника формат для обмена данными СРНС. RINEX - формат состоит из трех типов ASCII файлов - файлы метеорологических параметров (meteorological data file), файлы результатов измерений (observation data file), файлы с оперативной эфемеридной информацией, полученные в составе навигационного сообщения (navigation message file) [5].
Файлы имеют различную длину, максимальное значение равно 80 символам в строке (табл. 2). Каждый файл содержит секцию заголовков и секцию данных. Файл навигационного сообщения располагается независимо, в то время как файлы измерений и метеорологических данных должны быть созданы для каждого используемого при наблюдениях пункта [5].
Таблица 2. Общая структура формата RINEX:

Результаты измерений располагаются по эпохам. Каждой эпохе наблюдения соответствует структура, представленная на табл. 3 (количество и порядок расположения результатов различных типов измерений указывается в заголовке файла в строке "# / TYPES OF OBSERV", например, «7 LI L2C1 PI P2»), где у у mm dd hh mm sec момент приема сигнала по часам потребителя (tp); № - номера спутников, результаты наблюдений которых в соответствующем порядке записываются для каждой эпохи (при совместной обработке наблюдений ИСЗ обеих систем либо резервируются номера с 1 по 32 для спутников GPS и с 33 по 64 для спутников ГЛОНАСС, либо вводятся дополнительные признаки G и R); ИСЗ фаза L1 - псевдодальность, измеренная по фазе несущей на частоте L1; ИСЗ фаза L2 - псевдодальность, измеренная по фазе несущей на частоте L2; ИСЗ код С1 - псевдодальность, измеренная по С/А-коду на частоте L1; ИСЗ код Р1 - псевдодальность, измеренная по Р-коду на частоте L1; ИСЗ код Р2 - псевдодальность, измеренная по Р-коду на частоте L2 [2].
Таблица 3. Результаты СРНС-измерений на одну эпоху

Оперативная эфемеридная информация, полученная в составе навигационного сообщения, сгруппирована по номерам ИСЗ. Фрагменты файла измерений в формате RINEX представлены в прил. 2 [5].
GPS наблюдения включают в себя три основных понятия, которым необходимо дать определение: время, фаза и псевдодальность. Время измерений - это время приемника в момент приема сигналов. Оно одинаково для измерений фазы и псевдодальности и одинаково для всех наблюдаемых спутников в данную эпоху. Время выражается в единицах GPS-времени (не в мировом времени, UTC).
Псевдодальность (ПД) - это расстояние от приемной антенны до антенны спутника, включая сдвиги шкалы времени приемника и спутниковых часов (и другие сдвиги, такие как атмосферные задержки). Псевдодальность отражает реальное поведение часов приемника и передатчика. Псевдодальность указывается в единицах длины - метрах.
Фаза - это фаза несущей, измеренная в целых циклах. Измеряемое количество полуциклов квадратурными приемниками должно быть конвертировано в целые циклы и соответственно изменено значение длины волны в заголовке файла (только для GPS) [5].
Изменения фазы положительно коррелированны с изменениями дальности (негативный эффект Доплера). Фазовые наблюдения между эпохами должны быть скорректированы включением целого числа циклов. Фазовые наблюдения не будут содержать никаких систематических сдвигов от намеренных сдвигов опорных генераторов.
Данные всех измерений не скорректированы на внешние эффекты, такие как атмосферная рефракция, сдвиг часов спутникового передатчика и другие. Если приемник или программа конвертера производят измерения сдвига часов приемника в реальном времени dT(изм), то соответственно три параметра (фаза, псевдодальность, эпоха) должны быть исправлены. Знак доплеровского сдвига частоты определяется как обычно - положительный знак при приближении спутника [5].
Task:
Для дальнейшей обработки и сортировки данных мною была написана программа на языке С++, которая считывает файлы в RINEX формате и сортирует псевдодальности по каждому НС, что упрощает дальнейшую обработку. Для основной обработки данных по формуле 4.4 выполнялись вычисления с помощью редактора EXCEL.
# Разработка Парсинг данных в файлах.
Task:
Алгоритм.
# Разработка Парсинг данных в файлах.
Decision:
Из текстового файла вывести всю информацию до END OF HEADER в out.txt.
Вывести следующую строку после END OF HEADER - время и название спутников.
Вывести количество спутников и названия спутников в строке.
Вывести название спутников по буквам, то есть создаем динамический массив с указателем.
Вывести вторую строку название спутников.
Вывести буквы спутников в столбец.
Вывести по буквам и по цифрам. если увидим пробел, тогда операция не должна выполняться.
Вывести все спутники в столбец.
Вывести псевдодальности для одной/первой эпохи (время - 0:0).
Вывести названия спутников для первой эпохи.
Вывести псевдодальности для каждого спутника.
Вывести название спутника и расстояние (дальность) спутника. первая строка - для первой эпохи, вторая строка - для второй эпохи
Вывести для всех эпох данные спутников.
Вывести на экран данные для двух спутников.
Вывести данные именно для одного спутника, например первого.
Task:
Вывести названия спутников из файла для первой минуты.
# Разработка Парсинг данных в файлах.
Decision:
tuser@kvmubuntu:~$ cat IRKL1119.txt
2.11 OBSERVATION DATA M (MIXED) RINEX VERSION / TYPE
...
END OF HEADER
11 11 19 0 0 0.0000000 0 18G 1G28R22G1R12G 7G 3G 6R 6R24R 5G26-0.000381360
G11G16R13R14G 8R23
23815384.399 23815383.399 125150709.498 3 3673.062 23.000
...
tuser@kvmubuntu:~$ cat output.txt
G1
G28
R22
G1
R12
G7
G3
G6
R6
R24
R5
G26
G11
G16
R13
R14
G8
Task:
Читаем Каждую Букву И Цифру После строки названия спутников для первой минуты.
# Разработка Парсинг данных в файлах.
Decision:
tuser@kvmubuntu:~$ cat igs19236-1.txt
#cP2016 11 19 0 0 0.00000000 96 ORBIT IGb08 HLM IGS
...
* 2016 11 19 0 0 0.00000000
PG01 -20514.995126 -11031.142105 12884.404415 40.929190 7 8 4 99
PG02 12690.844622 22403.534044 7723.409365 523.430781 9 7 9 125
...
tuser@kvmubuntu:~$ cat out.txt
P
G
0
1
-
2
0
5
1
4
.
9
9
5
1
2
6
-
1
1
0
3
1
.
1
4
2
1
0
5
1
2
8
8
4
.
4
0
4
4
1
5
4
0
.
9
2
9
1
9
0
7
8
4
9
9
Task:
Мы Выводим Данные Спутников G16 В Текстовый Файл для каждой эпохи.
# Разработка Парсинг данных в файлах.
Decision:
tuser@kvmubuntu:~$ cat IRKL1119.txt
...
G11G16R13R14G 8R23
23815384.399 23815383.399 125150709.498 3 3673.062 23.000
23815389.819 97520038.895 3 2862.131 23.000
23418101.271 23418101.711 123062972.555 4 2734.873 26.000
23418102.171 95893253.756 4 2131.058 26.000
...
tuser@kvmubuntu:~$ cat output.txt
...
23418101.711
23402498.509
23386912.128
23371345.657
23355798.957
...
Task:
Выводим список спутников и их псевдоальность для первой эпохи.
# Разработка Парсинг данных в файлах.
Decision:
tuser@kvmubuntu:~$ cat output.txt
G1 G28 R22 G19 R12 G7 G3 G6 R6 R24 R5 G26 G11 G16 R13 R14 G9 R23
23815383.399 23418101.711 20126478.966 20576502.049 20850572.801 20361179.631 22177242.661 23871188.467 23896969.354 22949017.462 23330231.749 23194678.499 21898256.651 24811902.872 19151353.321 21666798.485 20650945.821 19472152.449 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Task:
Выводим количество спутников, название спутников и пссевдодальность для каждого спутника за первые 15 минут.
# Разработка Парсинг данных в файлах.
Decision:
tuser@kvmubuntu:~$ cat output.txt
18
G1
G28
R22
G19
R12
G7
G3
G6
R6
R24
R5
G26
G11
G16
R13
R14
G9
R23
18
G1
G28
R22
G19
R12
G7
G3
G6
R6
R24
R5
G26
G11
G16
R13
R14
G8
R23
18
G1
G28
R22
G19
R12
G7
G3
G6
R6
R24
R5
G26
G11
G16
R13
R14
G8
R23
1243988
19453454.30480937797.92821279.27712.000
19453454.30480937797.92821279.27712.000
G1 G28 R22 G19 R12 G7 G3 G6 R6 R24 R5 G26 G11 G16 R13 R14 G9 R23 G8 19453454.30480937797.92821279.27712.000
23815383.399 23418101.711 20126478.966 20576502.049 20850572.801 20361179.631 22177242.661 23871188.467 23896969.354 22949017.462 23330231.749 23194678.499 21898256.651 24811902.872 19151353.321 21666798.485 20650945.821 19472152.449 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
23794425.041 23402498.509 20141642.176 20584598.589 20869652.326 20367330.686 22196301.185 23890335.007 23883323.395 22925234.933 23334086.485 23188096.286 21881612.664 24830710.969 19148858.027 21645612.101 0 19462739.332 20642124.208 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
23773491.181 23386912.128 -2723.261 20592788.59 20888815.333 20373592.145 22215405.514 23909502.132 23869784.311 22901490.193 23338082.579 23181639.852 21865044.244 24849525.498 19146493.433 21624473.283 0 19453451.974 20633403.301 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 19453451.974 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Task:
Выведем данные Псевдодальности для каждого спутника.
# Разработка Парсинг данных в файлах.
Decision:
tuser@kvmubuntu:~$ cat IRKL1119.txt
2.11 OBSERVATION DATA M (MIXED) RINEX VERSION / TYPE
...
END OF HEADER
11 11 19 0 0 0.0000000 0 18G 1G28R22G19R12G 7G 3G 6R 6R24R 5G26-0.000381360
G11G16R13R14G 8R23
23815384.399 23815383.399 125150709.498 3 3673.062 23.000
23815389.819 97520038.895 3 2862.131 23.000
...
tuser@kvmubuntu:~$ cat output.txt
G1 G28 R22 G19 R12 G7 G3 G6 R6 R24 R5 G26 G11 G16 R13 R14 G8 R23 G15 G22 G17 R7 R15 R17 R8 G32 G20 G9 R1 R16 G4 R18 R2 G12 G2 R9 G10 G23 G25 R19 R10 G13 G5 R4 G31 R11 G29 R20 G30 G21 R21 G18 G14
23815383.399 23418101.711 20126478.966 20576502.049 20850572.801 20361179.631 22177242.661 23871188.467 23896969.354 22949017.462 23330231.749 23194678.499 21898256.651 24811902.872 19151353.321 21666798.485 20650945.821 19472152.449 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
23794425.041 23402498.509 20141642.176 20584598.589 20869652.326 20367330.686 22196301.185 23890335.007 23883323.395 22925234.933 23334086.485 23188096.286 21881612.664 24830710.969 19148858.027 21645612.101 20642124.208 19462739.332 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
...
Task:
Выведем данные из файла Sirftin.
# Разработка Парсинг данных в файлах.
Decision:
tuser@kvmubuntu:~$ cat sirfrin1.txt
2.10 OBSERVATION DATA G (GPS) RINEX VERSION / TYPE
...
END OF HEADER
15 5 18 0 41 23.0000613 0 11G 1G12G32G24G22G14G11G 4G18G31G17
23527987.056 8
21972648.359 8
22403365.951 6
23784621.452 7
21148286.543 6
20408196.378 4
24488332.428 4
23108442.059 5
23196661.017 4
22514486.129 5
25648439.341 3
15 5 18 0 41 24.0000613 0 11G 1G12G32G24G22G14G11G 4G18G31G17
23527900.192 8
21972620.569 8
22402887.237 5
23785272.449 7
21148685.515 6
20408150.444 4
24488620.925 4
23108699.683 5
23197296.183 4
22513871.405 5
25648503.069 3
...
tuser@kvmubuntu:~$ cat output.txt
G1 G12 G32 G24 G22 G14 G11 G4 G18 G31 G17 G3 G25 G26 G29
23527987.056 21972648.359 22403365.951 23784621.452 21148286.543 20408196.378 24488332.428 23108442.059 23196661.017 22514486.129 25648439.341 0 0 0 0
23527900.192 21972620.569 22402887.237 23785272.449 21148685.515 20408150.444 24488620.925 23108699.683 23197296.183 22513871.405 25648503.069 0 0 0 0
23527815.469 21972594.92 22402410.598 23785925.499 21149086.34 20408107.268 24488915.359 23108959.419 23197938.791 22513258.71 25648554.131 0 0 0 0
23527729.677 21972568.22 22401932.854 23786577.382 21149485.828 20408062.76 24489187.365 23109217.855 23198578.688 22512592.942 25648601.174 0 0 0 0
...
Task:
Нарисуйте График с файла Sirfrin1.
# Разработка Парсинг данных в файлах.
Task:
Нарисуйте График И Вычислите Разницу.
# Разработка Парсинг данных в файлах.
Task:
Попробуем просто сделать это все на графическом интерфейсе, вывести данные двух спутников, плюс еще нарисовать графики этих данных для двух спутников.
Теперь нужно обработать и сортировать данные с геометрической дальностью для спутников. Файл называется igr18451.txt. Вот как выглядят данные, которые нужно отсортировать. Тут уже одна эпоха равняется 15 минутам.
То что я выделил, это координаты спутника X,Y,Z. Именно их и нужно отсортировать. PG01 - название первого спутника. Попробуем вывести данные именно для него.
# Разработка Парсинг данных в файлах.
Decision:
PG04 16571.755106 7091.147720 19268.134634
PG04 17081.817393 9222.831883 17918.904800
PG04 17633.922784 11162.951350 16256.328779
PG04 18194.986791 12883.319207 14310.615388
PG04 18728.745598 14363.489413 12116.696076
PG04 19197.262350 15591.290270 9713.525830
PG04 19562.489921 16563.032391 7143.333216
PG04 19787.827341 17283.391677 4450.837454
PG04 19839.609715 17764.980464 1682.449322
PG04 19688.476298 18027.631365 -1114.528992
PG04 19310.568086 18097.427949 -3892.691773
PG04 18688.514262 18005.524210 -6605.294077
PG04 17812.175758 17786.800613 -9206.983073
PG04 16679.123638 17478.408399 -11654.488894
PG04 15294.839581 17118.255856 -13907.269035
PG04 13672.635233 16743.490595 -15928.101701
PG04 11833.296299 16389.030589 -17683.624513
PG04 9804.465824 16086.194088 -19144.815686
PG04 7619.789018 15861.474593 -20287.415200
...
Task:
Это мы вывели координаты X,Y,Z и название спутника. Но мне теперь нужно вывести данные только Х для первого спутника.
# Разработка Парсинг данных в файлах.
Decision:
14736.411108
15414.203154
16201.304785
17074.555745
18004.439905
18956.228081
19891.328698
20768.792721
21546.914135
...
Task:
Аналогично выводятся только для Y и Z выводим данные. Просто нужно поменять в коде x на y или z.
# Разработка Парсинг данных в файлах.
Task:
Аналогично нужно вывести данные псевдодальности полученные с моего приемника. файл - sirfrin1.txt.
Тут мы увидим только две данные для спутников. Первые, это дальность, которую как раз и нужно отсортировать по каждом НС, а вторые - сигналы спутника, которые нас не особо не интересуют. А также эпоха здесь начинается не с нуля, как мы видим, а с 41 минуты 23 секунды. Это тоже нужно учитывать, когда нужно будет сравнивать эти данные с ГД.
# Разработка Парсинг данных в файлах.
Decision:
Мы задачу выполнили (отсортировать данные ГД и ПД по каждом навигационному спутнику), остается только обработать эти данные по формулам и посторить по ним графики через Эксель.
Task:
Экспериментальные результаты.
# Спутниковые радионаввигационные системы.
Decision:
Для наглядности на рис. 14 показан пример измерения навигационных сигналов, принимаемых с НС GPS1 и GPS20, взятый из статьи [6]. По горизонтали отложены номера 30-ти секундных интервалов (эпох) от 0 часов всемирного времени. В верхней части рисунка даны результаты вычислений углов места НС GPS1 (пунктир) и GPS20 (точки). В нижней части рисунка тонкой линией в соответствии с формулой (3.4) показана разность измеренных псевдодальностей за вычетом разности ГД от этих НС с коррекцией запаздывания лучей в тропосфере по формуле (4.5). Для расчета ГД использовались уточненные эфемериды SP3 [6].
Рис. 14. Пример измерений вариаций ионосферы:
Здесь же для сравнения жирной линией приведена разность ионосферных ошибок для этих же НС по данным двухчастотного приемника JPS EGGDT станции Иркутск (IRKL).
На рис. 15 показана средняя часть рис. 14 для детального сравнения данных о вариациях ионосферной ошибки, определяемой вариациями ПЭС между двумя НС [6].
Рис.15. Сравнение данных одночастотного и двухчастотного приемников:
Видно, что для высоких углов места в среднем наблюдается хорошее совпадение результатов, полученных разными методами. Следует отметить, что случайные отклонения у одночастотного приемника примерно в два раза больше. При приближении НС к горизонту данные одночастотного приемника начинают сильно отличаться от двухчастотного, и при углах места около 5° различие доходит до 15-20 м (~ 60 нс). Вероятно, это связано с влиянием тропосферы и неучтенной при коррекции «влажной» составляющей тропосферной погрешности [6].
Приведенные данные свидетельствуют о близости результатов определения разности ионосферных ошибок двухчастотным и одночастотным приемниками. Как видно из сравнения описанных результатов, в диапазоне углов места больше 15° две кривые хорошо совпадают, различие между ними в 90% случаев не превышает 2 м (7 нс), при регулярном ходе около 20 м (70 нс) [6].
Для сравнения, я пытался построить свои примеры измерения навигационных сигналов. В прил. 3 показан код программы на языке С++, которая обрабатывает и сортирует данные ПД по каждому НС. На табл. 4 показан пример вычислений и интерпретаций данных с помощью EXCEL:
Таблица 4. Вычисления данных с помощью Excel:
где x, y, z – координаты приёмника, а Xi, Yi, Zi – координаты спутника, ГД- вычисленная по формуле (4.1) геометрическая дальность, ПД – пседодальность и последний столбец является разностью ошибок ионосферы для двух спутников G1и G28 вычисленная по формуле (4.4).
На рис. 16-19 построены разности ошибок ионосферы для двух НС в один момент времени. Первая часть данных взяты из собственных измерений, а вторая часть данных для сравнения давались мне руководителем. По горизонтали отложены номера 15-ти минутных интервалов.
Рис. 16. Пример измерений, принимаемых с GPS 1 и GPS 28, Рис. 17. Пример измерений, принимаемых с GPS 20 и GPS 32, Рис. 18. Пример измерений, принимаемых с GPS 2 и GPS 5, Рис. 19. Пример измерений, принимаемых с GPS 1 и GPS 4:
Разность псевдодальности и геометрической дальности на рис. 16-17 является разностью ионосферной задержки и может быть использована для коррекции ионосферы. На рис. 18-19 получились большие разности, и такие данные использовать для уточнения состояния ионосферы при её оперативной коррекции нельзя.
Decision:
Для защиты диссертации по теме "Использование данных с одночастотных приемников спутниковых радионавигационных систем для коррекции модели ионосферы" освоил технологию приёма получения данных с одночастотных приемников спутниковых радионавигационных систем, получил данные, разработал программу на C++, которая обрабатывает и сортирует данные двух координат из файла по столбцам, рисует график, чтобы увидеть желаемый результат в точности определения координат спутников, рассмотрел способы уменьшения ошибок измерения псевдодальности и показал, что из-за нестабильности аппаратуры потребителя информация о состоянии ионосферы может быть получена в каждый момент времени по разностям ПД двух навигационных спутников
Decision:
Защитил диплом выпускной квалификационной работы бакалавра и магистерскую диссертацию.
Source:
# https://forum.calculate-linux.org/t/windows-qemu-kvm-libvirt/9357
# https://blog.sedicomm.com/2019/07/21/rdesktop-klient-rdp-dlya-podklyucheniya-rabochego-stola-windows-iz-linux/
# https://learn.microsoft.com/ru-ru/windows-server/administration/openssh/openssh_install_firstuse
# https://learn.microsoft.com/ru-ru/powershell/scripting/learn/remoting/ssh-remoting-in-powershell-core?view=powershell-7.3
# https://learn.microsoft.com/en-us/powershell/module/storage/dismount-diskimage?view=windowsserver2022-ps
# https://superuser.com/questions/499264/how-can-i-mount-an-iso-via-powershell-programmatically
# https://winitpro.ru/index.php/2016/03/31/sftp-ssh-ftp-na-windows-server-2012-r2/
# https://mhelp.pro/ru/kak-zapustit-powershell-ot-imeni-administratora/?ysclid=lmzwqntxfi559273426
# https://remontka.pro/text-files-cmd-powershell/?ysclid=lmzy2p5172409325479
# https://www.digitalocean.com/community/tutorials/sftp-ru
# http://ftp.glonass-iac.ru/guide/navfaq.php
# https://ru.wtuseripedia.org/wtuseri/%D0%A1%D0%BF%D1%83%D1%82%D0%BD%D0%B8%D0%BA%D0%BE%D0%B2%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D0%BD%D0%B0%D0%B2%D0%B8%D0%B3%D0%B0%D1%86%D0%B8%D0%B8
# Харисов В.Н. Глобальная спутниковая радионавигационная система ГЛОНАСС
# Грудинская Г.П. Распространение радиоволн
# http://begin.clan.su/news/speciftusera_provedenija_psevdodalnomernykh_i_fazov/2013-09-18-135
# http://rrv.iszf.irk.ru/sites/default/files/conf2014/articles/tom2/17-20.pdf
# http://www.u-blox.com
# Дэвис К. Радиоволны в ионосфере
# https://www.youtube.com/watch?v=bDvVosvyVp0&list=LL&index=315
2015-03-01 - 2015-06-30: Green Orange, Иркутск. Должность: Веб-программист Достижения: Разработал сайт портфолио, в котором публиковал все решенные мной интересные задачи, отчеты лабораторных работ и презентации Дополнительная информация: Верстка Веб-страниц
Show more
Services:
# Верстка Веб-страниц.
# Администрирование Веб-серверов.
# Разработка баз данных.
# Написание Sql запросов.
# Администрирование баз данных.
# Администрирование локальных серверов.
Task:
Сверстать страницу портфолио.
# Верстка Веб-страниц.
Decision:

Ссылка на репозиторий: github.com
Мой сайт: dato138it.ru
Task:
Установка Apache2.
# Администрирование Веб-серверов.
Decision:
root@kvmubuntu:~# apt install apache2
root@kvmubuntu:~# ufw app list
Available applications:
Apache
Apache Full
Apache Secure
OpenSSH
root@kvmubuntu:~# ufw allow 80
root@kvmubuntu:~# ufw status
Status: active
To Action From
...
80 ALLOW Anywhere
80 (v6) ALLOW Anywhere (v6)
tuser@kvmubuntu:~$ google-chrome http://tipubuntu:80
Task:
Установка и настройка Mysql.
# Администрирование баз данных.
Decision:
root@kvmubuntu:~# apt install mysql-server
root@kvmubuntu:~# mysql
mysql> ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'tpassword';
mysql> exit
root@kvmubuntu:~# mysql_secure_installation
...
Press y|Y for Yes, any other key for No: y
Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 1
Change the password for root ? ((Press y|Y for Yes, any other key for No) : n
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : n
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
root@kvmubuntu:~# mysql -u root -p
mysql> SELECT user,authentication_string,plugin,host FROM mysql.user;
mysql> rename user 'root'@'localhost' to 'tuser'@'localhost';
mysql> create database tbase;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| tbase |
...
+--------------------+
mysql> exit
Task:
Добавление учетной записи к базе данных.
# Администрирование баз данных.
Decision:
mysql> CREATE USER 'tuser'@'%' IDENTIFIED BY 'tpassword';
mysql> GRANT ALL ON tbase.* TO 'tuser'@'%';
mysql> exit
tuser@kvmubuntu:~$ mysql -u tuser -p
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| performance_schema |
| tbase |
+--------------------+
3 rows in set (0.07 sec)
Task:
Настройка Lamp.
# Администрирование Веб-серверов.
Decision:
root@kvmubuntu:~# apt install php libapache2-mod-php php-mysql
root@kvmubuntu:~# php -v
PHP 8.1.2-1ubuntu2.18 (cli) (built: Jun 14 2024 15:52:55) (NTS)
...
root@kvmubuntu:~# vim /etc/php/8.1/apache2/php.ini
root@kvmubuntu:~# cat /etc/php/8.1/apache2/php.ini | grep upload_max_filesize
...
upload_max_filesize = 32M
post_max_size = 48M
memory_limit = 256M
max_execution_time = 600
max_input_vars = 3000
max_input_time = 1000
root@kvmubuntu:~# service apache2 restart
root@kvmubuntu:~# mkdir /var/www/dato138it
root@kvmubuntu:~# chown -R $USER:$USER /var/www/dato138it
root@kvmubuntu:~# vim /etc/apache2/sites-available/dato138it.conf
root@kvmubuntu:~# cat /etc/apache2/sites-available/dato138it.conf
<VirtualHost *:80>
ServerName dato138it
ServerAlias www.dato138it
ServerAdmin tmail138@mail.ru
DocumentRoot /var/www/dato138it
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
root@kvmubuntu:~# a2ensite dato138it
root@kvmubuntu:~# a2dissite 000-default
root@kvmubuntu:~# apache2ctl configtest
root@kvmubuntu:~# systemctl reload apache2
root@kvmubuntu:~# vim /var/www/dato138it/index.html
root@kvmubuntu:~# google-chrome http://tipubuntu:80
root@kvmubuntu:~# cat /etc/apache2/mods-enabled/dir.conf
<IfModule mod_dir.c>
DirectoryIndex index.html index.cgi index.pl index.php index.xhtml index.htm
</IfModule>
# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
root@kvmubuntu:~# systemctl reload apache2
root@kvmubuntu:~# vim /var/www/dato138it/info.php
root@kvmubuntu:~# google-chrome http://tipubuntu:80/info.php
Task:
Разработать схему БД.
# Разработка баз данных.
Decision:
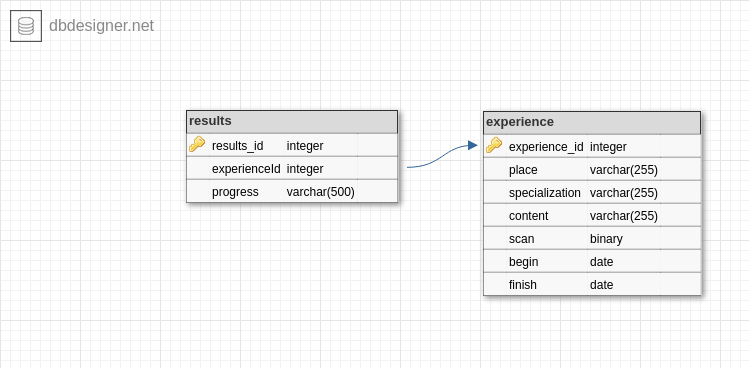
Task:
Создание таблиц.
# Разработка Sql таблиц Портфолио.
Decision:
mysql> create table tbase.ttable1
(ttable1_id INT PRIMARY KEY AUTO_INCREMENT,
content VARCHAR(255));
CREATE TABLE tbase.ttable1
(ttable1_id INT PRIMARY KEY AUTO_INCREMENT,
column1 VARCHAR(255),
column2 VARCHAR(255),
column3 VARCHAR(255),
column4 VARCHAR(255),
column5 Date,
column6 Date);
mysql> INSERT INTO tbase.ttable1
(column1, column2)
VALUES
("text1","text2"),
("text3","text4"),
("text5","text6"),
("text7","text8");
mysql> select * from tbase.ttable1;
+------------+---------+---------+---------+---------+---------+---------+
| ttable1_id | column1 | column2 | column3 | column4 | column5 | column6 |
+------------+---------+---------+---------+---------+---------+---------+
| 1 | text1 | text2 | NULL | NULL | NULL | NULL |
| 2 | text3 | text4 | NULL | NULL | NULL | NULL |
| 3 | text5 | text6 | NULL | NULL | NULL | NULL |
| 4 | text7 | text8 | NULL | NULL | NULL | NULL |
+------------+---------+---------+---------+---------+---------+---------+
4 rows in set (0.00 sec)
mysql> CREATE TABLE tbase.ttable2
(ttable2_id INT PRIMARY KEY AUTO_INCREMENT,
columnId INT,
column1 VARCHAR(500),
FOREIGN KEY (columnId) REFERENCES tbase.ttable1 (ttable1_id));
mysql> INSERT INTO tbase.ttable2
(columnId, column1)
VALUES
(1, "text9"),
(1, "text10"),
(2, "text11"),
(3, "text12"),
(4, "text13");
mysql> select * from tbase.ttable2;
+------------+----------+---------+
| ttable2_id | columnId | column1 |
+------------+----------+---------+
| 1 | 1 | text9 |
| 2 | 1 | text10 |
| 3 | 2 | text11 |
| 4 | 3 | text12 |
| 5 | 4 | text13 |
+------------+----------+---------+
5 rows in set (0.00 sec)
Task:
Выборка данных из двух таблиц.
# Написание Sql запросов.
Decision:
mysql> select * from tbase.ttable2
inner join tbase.ttable1
on ttable1.ttable1_id = ttable2.columnId;
+------------+----------+---------+------------+---------+---------+---------+---------+---------+---------+
| ttable2_id | columnId | column1 | ttable1_id | column1 | column2 | column3 | column4 | column5 | column6 |
+------------+----------+---------+------------+---------+---------+---------+---------+---------+---------+
| 1 | 1 | text9 | 1 | text1 | text2 | NULL | NULL | NULL | NULL |
| 2 | 1 | text10 | 1 | text1 | text2 | NULL | NULL | NULL | NULL |
| 3 | 2 | text11 | 2 | text3 | text4 | NULL | NULL | NULL | NULL |
| 4 | 3 | text12 | 3 | text5 | text6 | NULL | NULL | NULL | NULL |
| 5 | 4 | text13 | 4 | text7 | text8 | NULL | NULL | NULL | NULL |
+------------+----------+---------+------------+---------+---------+---------+---------+---------+---------+
5 rows in set (0.00 sec)
mysql> exit
Source:
# https://metanit.com/sql/mysql/2.5.php
# https://metanit.com/sql/mysql/5.2.php
Task:
Настройка Php.
# Администрирование Веб-серверов.
Decision:
root@kvmubuntu:~# vim /var/www/dato138it/index.php
root@kvmubuntu:~# google-chrome http://tipubuntu/index.php
Task:
Настройка Phpmyadmin.
# Администрирование Веб-серверов.
Decision:
root@kvmubuntu:~# apt install phpmyadmin php-mbstring php-zip php-gd php-json php-curl
...
Configure database for phpmyadmin with dbconfig-common? [yes/no] y
granting access to database phpmyadmin for phpmyadmin@localhost: failed.
error encountered creating user:
mysql said: ERROR 1819 (HY000) at line 1: Your password does not satisfy the current policy requirements
An error occurred while installing the database:
mysql said: ERROR 1819 (HY000) at line 1: Your password does not satisfy the current policy requirements . Your options are:
* abort - Causes the operation to fail; you will need to downgrade,
reinstall, reconfigure this package, or otherwise manually intervene
to continue using it. This will usually also impact your ability to
install other packages until the installation failure is resolved.
* retry - Prompts once more with all the configuration questions
...
1. abort 2. retry 3. retry (skip questions) 4. ignore
Next step for database installation: 1
...
Errors were encountered while processing:
phpmyadmin
needrestart is being skipped since dpkg has failed
E: Sub-process /usr/bin/dpkg returned an error code (1)
root@kvmubuntu:~# mysql -u tuser -p
mysql> UNINSTALL COMPONENT "file://component_validate_password";
mysql> exit
root@kvmubuntu:~# apt install phpmyadmin
root@kvmubuntu:~# apt install php8.1-fpm php8.1 libapache2-mod-php8.1 php8.1-common php8.1-mysql php8.1-xml php8.1-xmlrpc php8.1-imagick php8.1-cli php8.1-imap php8.1-opcache php8.1-soap php8.1-intl php8.1-bcmath unzip
root@kvmubuntu:~# mysql -u tuser -p
mysql> INSTALL COMPONENT "file://component_validate_password";
mysql> exit
root@kvmubuntu:~# phpenmod mbstring
root@kvmubuntu:~# systemctl restart apache2
root@kvmubuntu:~# cp /etc/phpmyadmin/apache.conf /etc/apache2/conf-available/phpmyadmin.conf
root@kvmubuntu:~# a2enconf phpmyadmin.conf
root@kvmubuntu:~# systemctl reload apache2
root@kvmubuntu:~# google-chrome http://tipubuntu/phpmyadmin
Source:
# https://bozza.ru/art-260.html
# https://www.digitalocean.com/community/tutorials/how-to-install-linux-apache-mysql-php-lamp-stack-on-ubuntu-22-04
# https://losst.pro/ustanovka-chrome-v-ubuntu-18-04?ysclid=lmdflkvc3v463974954
# https://qna.habr.com/q/439469?ysclid=lmdgkb49q827401606
# https://steptuser.org/course/63054/syllabus
# https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-phpmyadmin-on-ubuntu-20-04
# https://serverspace.ru/support/help/osnovnye-komandy-ufw/
# https://www.tutsmake.com/how-to-install-lamp-apache-mysql-php-in-ubuntu-22-04/
# https://www.php.net/manual/ru/faq.html.php
# https://www.8host.com/blog/kak-rabotayut-stroki-v-php/
# https://www.youtube.com/watch?v=FxwPQkP3OGY&t=611s
# https://timeweb.com/ru/community/articles/kak-ustanovit-stek-lamp-na-ubuntu-20-04
# https://wiki.merionet.ru/articles/perenos-bazy-dannyx-mysql-so-starogo-na-novyj-server
2023-11-01 - 2024-05-30: Информационно-аналитический центр поддержки ГАС правосудие, Иркутск. Должность: Инженер 2 категории / Системный администратор. Достижения: Разработал скрипты, которые автоматизируют процессы резервного копирования базы данных перед обновлением программы ГАС правосудие Дополнительная информация: Обязанности - работа с сайтами, поддержка функционирования серверов и сервисов СУБД, техническая поддержка пользователей. Навыки - Виртуализация, Windows, Sql.
Show more
Services:
# Разработка Бэкап.
# Администрирование локальных серверов.
Task:
Написать скрипт, который перед обновлением системы ГАС правосудие каждой ночью останавливает базу данных, делает бэкап базы на другой сервер и стартует бэкап.
# Разработка Бэкап.
Decision:
ЗДЕСЬ БУДЕТ ИНФОРМАЦИЯ
Task:
Добавить расписание.
# Администрирование локальных серверов.
Decision:
- Планировщик задач - Создать задачу - Имя - Backup- +Выполнить для всех пользователей - Триггеры - +Еженедельно - Начать - суббота - 23:00 - ок - действия - запуск программы - Программа или сценарий - powershell.exe - добавить аргументы
-file "C:\Users\tuser\Documents\scripts\backups\mrbtsbackup.ps1"
- ок
2024-06-02 - None: Tele2, Иркутск. Должность: Инженер эксплуатации подсистемы базовых станций. Достижения: Разработал скрипт, который делает бэкап файлов конфигураций базовых станций Дополнительная информация: Обязанности - Обеспечивать эксплуатацию оборудования контроллеров и базовых станций стандартов 2G/3G/4G, Обеспечивать локальную поддержку работ по аварийному восстановлению работоспособности оборудования контроллеров, Поддерживать ввод в работу новых узлов контроллеров базовых станций, Предоставлять техническую поддержку инженерам по вопросам работы подсистемы базовых станций. Навыки - Sql, Python, Ericsson, Nokia, Vba
Show more
Services:
# Разработка Бэкап.
# Администрирование локальных серверов.
Task:
Написать скрипт, который копирует файлы с ftp://tipftp/Backups/tdir/MRBTS* в сетевую папку \\tdomain.ru\tdir каждую неделю ночью.
# Разработка Бэкап.
Decision:
PS C:\Windows\system32> backup1.bat
PS C:\Windows\system32> ls .\new1\
Каталог: C:\Users\tuser\Documents\scripts\new1
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 05.09.2024 14:21 test
d----- 05.09.2024 14:18 test2
PS C:\Windows\system32> ls .\new1\test\
Каталог: C:\Users\tuser\Documents\scripts\new1\test
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 05.09.2024 14:17 Новая папка
d----- 05.09.2024 14:18 Новая папка (2)
-a---- 05.09.2024 14:00 3 test.txt
-a---- 05.09.2024 14:00 3 test2.txt
Task:
Подключиться к ftp и скопировать файлы в сетевую папку.
# Администрирование локальных серверов.
Decision:
PS C:\Windows\system32> ftp
ftp> open tipftp
ftp> tuser
ftp> ls Backups/tdir
ftp> get /Backups/tdir/MRBTS2279.xml \\tdomain.ru\tdir\Test.txt
200 PORT command successful. Consider using PASV.
150 Opening BINARY mode data connection for /Backups/tdir/MRBTS2279.xml (126410 bytes).
226 Transfer complete.
ftp: 126410 байт получено за 0.24 (сек) со скоростью 533.38 (КБ/сек).
Task:
Добавить раписание.
# Администрирование локальных серверов.
Decision:
- Планировщик задач - Создать задачу - Имя - Backup MTBTS - +Выполнить для всех пользователей - Триггеры - +Еженедельно - Начать - суббота - 23:00 - ок - действия - запуск программы - Программа или сценарий - powershell.exe - добавить аргументы
-file "C:\Users\tuser\Documents\scripts\backups\mrbtsbackup.ps1"
- ок
Source:
# https://comp-security.net/%D0%BA%D0%B0%D0%BA-%D1%81%D0%BA%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D1%82%D1%8C-%D1%84%D0%B0%D0%B9%D0%BB-%D0%BF%D0%B0%D0%BF%D0%BA%D1%83-%D0%B2-cmd/ - Как скопировать файл (папку) в командной строке Windows.
# https://pc.ru/articles/kak-dobavit-kommentarii-v-bat-fajl - Как добавить комментарии в bat-файл.
# https://learn.microsoft.com/ru-ru/powershell/module/microsoft.powershell.utility/get-date?view=powershell-7.4 - Get-Date.
# https://learn.microsoft.com/ru-ru/powershell/module/microsoft.powershell.management/remove-item?view=powershell-7.4 - Remove-Item.
# https://learn.microsoft.com/ru-ru/powershell/module/microsoft.powershell.utility/write-output?view=powershell-7.4 - Write-Output.
# https://docs.oracle.com/cd/E19120-01/open.solaris/819-1634/remotehowtoaccess-87541/index.html - How to Copy Files From a Remote System (ftp).
# http://forum.oszone.net/post-2962057.html - Powershell. Копировать файлы в новую dir, созданную с именем текущей даты.
# https://windowsnotes.ru/powershell-2/zapusk-powershell-skripta-po-raspisaniyu/ - Способ 1.
# https://stackoverflow.com/questions/18180060/how-to-zip-a-file-using-cmd-line - How to zip a file using cmd line?
# https://learn.microsoft.com/ru-ru/windows-server/administration/windows-commands/del - del.
# https://www.dmosk.ru/miniinstruktions.php?mini=7zip-cmd - Резервное копирование с помощью 7-Zip.
# https://docs.python.org/3/library/venv.html - Creating virtual environments.
# https://realpython.com/python-coding-setup-windows/#installing-python-with-pyenv-for-windows - Installing Python With pyenv for Windows.
# https://wiki.merionet.ru/articles/kak-opredelit-versiyu-linux#:~:text=%D0%A1%D0%B0%D0%BC%D1%8B%D0%B9%20%D0%BF%D1%80%D0%BE%D1%81%D1%82%D0%BE%D0%B9%20%D1%81%D0%BF%D0%BE%D1%81%D0%BE%D0%B1%20%D0%BF%D1%80%D0%BE%D0%B2%D0%B5%D1%80%D0%B8%D1%82%D1%8C%20%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D1%8E,%D0%B2%D0%BC%D0%B5%D1%81%D1%82%D0%B5%20%D1%81%20%D0%BA%D0%BE%D0%BD%D0%BA%D1%80%D0%B5%D1%82%D0%BD%D0%BE%D0%B9%20%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D0%B5%D0%B9%20%D1%8F%D0%B4%D1%80%D0%B0. - Как определить версию Linux?
2024-06-02 - None: Tele2, Иркутск Должность: Инженер эксплуатации подсистемы базовых станций. Достижения: Автоматизировал процесс заполнения данных на сайте. Дополнительная информация: Обязанности - Обеспечивать эксплуатацию оборудования контроллеров и базовых станций стандартов 2G/3G/4G, Обеспечивать локальную поддержку работ по аварийному восстановлению работоспособности оборудования контроллеров, Поддерживать ввод в работу новых узлов контроллеров базовых станций, Предоставлять техническую поддержку инженерам по вопросам работы подсистемы базовых станций. Навыки - Sql, Python, Ericsson, Nokia, Vba.
Show more
Task:
Главная цель задачи - автоматизировать процесс заполнения сайта для данных 2G, 3G, 4G Nokia и Ericsson.
Decision:
Цель выполнена.
Программа выгружает из сайта CES через БД информацию по незаполненным полям в таблицах, общую информацию по довесам и координаты, из сайта RDB координаты БС и данные по УЦН, обрабатывает все полученные данные и заполняет отчет в виде файлов с готовыми данными. полученные файлы программа автоматически импортирует библиотекой Selenium на сайт CES.
Порядок запуска:
- Перед запуском программы нужно установить Python версии выше 3.10, браузер Chrome и инструмент для парсинг данных на сайтах Chrome driver последней версии.
- Перед запуском программы необходимо заполнить данные в файле main/ces_v*/config.txt
- Для запуска программы в папке main есть скрипт startWin_v*.bat. скрипт автоматически создает папку с проектом на диске с папкой для переменных окружения в python и временная папка для работы проекта и запускает проект во временной папке. после того как скрипт завершится работа проекта, из временной папки выгружаются логи в папку с проектом и удаляется временная папка.
- в папке tools есть инструменты. querryManager выполняется для работы с базой данных, например, найти какую-нибудь информацию в базе. unloadingCoordsOldBS - парсит данные координат довесов. encoding выполняется для проверки кодировки файлов, импортируемых на сайт.
Исходники: https://github.com/it38dato/AutomatizationDataSite
2011-09-01 - 2018-05-30: Иркутский государственный университет, Иркутск. Должность: Информационные технологии и телекоммуникационные системы - Бакалавр / Электроника и наноэлектроника - Магистр / Информационная безопасность - Дополнительное образование. Достижения: Для защиты выпускной экзаменационной работы по теме "Утилита для сканирования безопасности сети Nmap" подготовил несколько тестовых виртуальных машин ОС, настроил Vsftpd-сервер, Nginx-сервер, Proxy-сервер, просканировал виртуальные машины и настроил Iptables. Дополнительная информация: Навыки - Windows, Виртуализация, Linux, Bash.
Show more
Services:
# Анализ сетевых технологий.
# Написаниие скриптов.
Task:
Выводим список текущих правил iptables и проанализируем какие порты открыты в сервере Centos.
# Анализ сетевых технологий.
Decision:
┌──(tuser㉿kvmkali)-[~]
└─$ nmap tipcentos
[root@kvmcentos ~]# yum install iptables-services
[root@kvmcentos ~]# iptables --version
[root@kvmcentos ~]# iptables -L -v
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
[root@kvmcentos ~]# systemctl start iptables
[root@kvmcentos ~]# systemctl enable iptables
[root@kvmcentos ~]# service iptables status
┌──(tuser㉿kvmkali)-[~]
└─$ nmap tipcentos
...
PORT STATE SERVICE
22/tcp open ssh
Task:
В сервере Centos Напишем набор правил iptables, в котором мы разрешаем все исходящие соединения и строго ограничиваем входящие.
Доступ будет возможен по портам TCP: 21, 22, 25, 53, 80, 143, 443, по портам UDP: 20, 21, 53, также мы пропускаем пакеты для уже установленных соединений.
С удаленной машины просканируем порты на нашем сервере.
# Написание скриптов.
Decision:
[root@kvmcentos ~]# chmod +x firewall.sh
[root@kvmcentos ~]# ./firewall.sh
[root@kvmcentos ~]# iptables -L -v
Chain INPUT (policy DROP 1986 packets, 87384 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT all -- lo any anywhere anywhere
79 5604 ACCEPT all -- any any anywhere anywhere state RELATED,ESTABLISHED
9 396 ACCEPT tcp -- any any anywhere anywhere multiport dports ftp,ssh,smtp,domain,http,imap,https
0 0 ACCEPT udp -- any any anywhere anywhere multiport dports domain,ftp,ftp-data
0 0 ACCEPT icmp -- any any anywhere anywhere icmp echo-reply
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT all -- any lo anywhere anywhere
60 7920 ACCEPT all -- any any anywhere anywhere state NEW,RELATED,ESTABLISHED
[root@kvmcentos ~]# service iptables save
┌──(tuser㉿kvmkali)-[~]
└─$ nmap tipcentos
...
PORT STATE SERVICE
21/tcp closed ftp
22/tcp open ssh
25/tcp closed smtp
53/tcp closed domain
80/tcp closed http
143/tcp closed imap
443/tcp closed https
...
Source:
# https://blog.sedicomm.com/2016/12/16/iptables-ustanovka-i-nastrojka/?ysclid=ln3wplng53988958006#1
Task:
Обнаружим активные устройства в сети.
# Анализ сетевых технологий.
Decision:
┌──(tuser㉿kvmkali)-[~]
└─$ apt install nmap
┌──(tuser㉿kvmkali)-[~]
└─$ nmap -sL tipcentos/24
...
Nmap scan report for KvmKali (tipkali)
...
Nmap scan report for kvmcentos (tipcentos)
...
Nmap scan report for kvmubuntu (tipubuntu)
...
Task:
Просканируем хост и проанализируем порт ftp. В некоторых случаях можно вытащить логин и пароль. Такое происходит, когда используются параметры входа по умолчанию.
# Анализ сетевых технологий.
Decision:
[root@kvmcentos ~]# nmap -sV tipcentos
...
PORT STATE SERVICE VERSION
21/tcp open ftp vsftpd 3.0.5
22/tcp open ssh OpenSSH 8.7 (protocol 2.0)
80/tcp open http nginx 1.22.1
3128/tcp open http-proxy Squid http proxy 5.5
...
[root@kvmcentos ~]# nmap -sC tipcentos -p 21
...
PORT STATE SERVICE
21/tcp open ftp
...
root@aw:/# find /usr/share/nmap/scripts/ -name '*.nse' | grep ftp
...
/usr/share/nmap/scripts/ftp-brute.nse
...
root@aw:/# nmap --script-help ftp-brute.nse
...
Performs brute force password auditing against FTP servers.
...
[root@kvmcentos ~]# nmap --script ftp-brute.nse tipcentos -p 21
...
PORT STATE SERVICE
21/tcp open ftp
| ftp-brute:
| Accounts: No valid accounts found
| Statistics: Performed 324 guesses in 642 seconds, average tps: 7.5
|_ ERROR: The service seems to have failed or is heavily firewalled...
...
Task:
Сканируем диапазон портов.
# Анализ сетевых технологий.
Decision:
┌──(tuser㉿kvmkali)-[~]
└─$ nmap -sT -p 21-80 tipcentos
...
PORT STATE SERVICE
21/tcp open ftp
22/tcp open ssh
25/tcp closed smtp
53/tcp closed domain
Task:
Просканируем удаленный хост (агрессивный режим).
# Анализ сетевых технологий.
Decision:
┌──(tuser㉿kvmkali)-[~]
└─$ nmap -A -T4 tipcentos
...
PORT STATE SERVICE VERSION
20/tcp closed ftp-data
21/tcp open ftp vsftpd 3.0.5
22/tcp open ssh OpenSSH 8.7 (protocol 2.0)
25/tcp closed smtp
53/tcp closed domain
143/tcp closed imap
443/tcp closed https
3128/tcp open http-proxy Squid http proxy 5.5
|_http-server-header: squid/5.5
|_http-title: ERROR: The requested URL could not be retrieved
MAC Address: tmaccentos (QEMU virtual NIC)
Aggressive OS guesses: Linux 2.6.32 - 3.13 (94%), Linux 2.6.22 - 2.6.36 (92%), Linux 3.10 (92%), Linux 3.10 - 4.11 (92%), Linux 2.6.39 (92%), Linux 2.6.32 (91%), Linux 3.2 - 4.9 (91%), Linux 2.6.32 - 3.10 (91%), Linux 2.6.18 (90%), Linux 3.16 - 4.6 (90%)
No exact OS matches for host (test conditions non-ideal).
Network Distance: 1 hop
Service Info: OS: Unix
TRACEROUTE
HOP RTT ADDRESS
1 0.83 ms tipcentos
OS and Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 24.18 seconds
Source:
# https://losst.ru/kak-polzovatsya-nmap-dlya-skanirovaniya-seti
Task:
Перехватываем DNS-трафик между сервером и каким-нибудь узлом в сети.
# Анализ сетевых технологий.
Decision:
┌──(tuser㉿kvmkali)-[~]
└─$ nmap tipwindows12
...
PORT STATE SERVICE
53/tcp open domain
80/tcp open http
443/tcp open https
...
[root@kvmcentos ~]# tcpdump -i enp1s0 -n -nn -ttt 'host tipwindows12 and port 53'
Task:
Перехватываем весь трафик для MAC-адреса tmaccentos на сетевом интерфейсе enp1s0.
# Анализ сетевых технологий.
Decision:
[root@kvmcentos ~]# ifconfig
enp1s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
...
ether tmaccentos txqueuelen 1000 (Ethernet)
...
[root@kvmcentos ~]# tcpdump -n -i enp1s0 "ether host tmaccentos"
...
┌──(tuser㉿kvmkali)-[~]
└─$ ssh tuser@tipcentos
[root@kvmcentos ~]# tcpdump -n -i enp1s0 "ether host tmaccentos"
...
00:11:12.536934 IP tipcentos.58598 > tipubuntu.22: Flags [.], ack 3730, win 501, options [nop,nop,TS val 3107339434 ecr 2462889902], length 0
00:11:12.586762 IP tipubuntu.22 > tipcentos.58598: Flags [P.], seq 3730:3782, ack 2242, win 501, options [nop,nop,TS val 2462889993 ecr 3107339434], length 52
00:11:12.586838 IP tipubuntu.22 > tipcentos.58598: Flags [P.], seq 3782:3898, ack 2242, win 501, options [nop,nop,TS val 2462889993 ecr 3107339434], length 116
00:11:12.588205 IP tipcentos.58598 > tipubuntu.22: Flags [.], ack 3782, win 501, options [nop,nop,TS val 3107339485 ecr 2462889993], length 0
00:11:12.588207 IP tipcentos.58598 > tipubuntu.22: Flags [.], ack 3898, win 501, options [nop,nop,TS val 3107339486 ecr 2462889993], length 0
Task:
Перехватываем только ICMP-пакеты.
# Анализ сетевых технологий.
Decision:
[root@kvmcentos ~]# tcpdump -i enp1s0 -n -nn -ttt 'ip proto \icmp'
...
┌──(tuser㉿kvmkali)-[~]
└─$ ping tipcentos
...
64 bytes from tipcentos: icmp_seq=1 ttl=64 time=0.692 ms
64 bytes from tipcentos: icmp_seq=2 ttl=64 time=0.764 ms
64 bytes from tipcentos: icmp_seq=3 ttl=64 time=0.868 ms
64 bytes from tipcentos: icmp_seq=4 ttl=64 time=1.01 ms
64 bytes from tipcentos: icmp_seq=5 ttl=64 time=1.13 ms
^C
...
[root@kvmcentos ~]# tcpdump -i enp1s0 -n -nn -ttt 'ip proto \icmp'
...
00:00:00.000000 IP tipcentos > tipubuntu: ICMP echo request, id 4, seq 1, length 64
00:00:00.000171 IP tipubuntu > tipcentos: ICMP echo reply, id 4, seq 1, length 64
00:00:01.001145 IP tipcentos > tipubuntu: ICMP echo request, id 4, seq 2, length 64
00:00:00.000077 IP tipubuntu > tipcentos: ICMP echo reply, id 4, seq 2, length 64
00:00:01.001365 IP tipcentos > tipubuntu: ICMP echo request, id 4, seq 3, length 64
00:00:00.000077 IP tipubuntu > tipcentos: ICMP echo reply, id 4, seq 3, length 64
00:00:01.001375 IP tipcentos > tipubuntu: ICMP echo request, id 4, seq 4, length 64
00:00:00.000077 IP tipubuntu > tipcentos: ICMP echo reply, id 4, seq 4, length 64
00:00:01.001573 IP tipcentos > tipubuntu: ICMP echo request, id 4, seq 5, length 64
00:00:00.000125 IP tipubuntu > tipcentos: ICMP echo reply, id 4, seq 5, length 64
Task:
Перехватываем входящий трафик на порт 80. сохраняем статистику в файл my.log для первых 500 пакетов. Будет создан бинарный файл my.log.
# Анализ сетевых технологий.
Decision:
[root@kvmcentos ~]# tcpdump -v -i enp1s0 dst port 80
...
┌──(tuser㉿kvmkali)-[~]
└─$ firefox tipcentos:80
[root@kvmcentos ~]# tcpdump -v -i enp1s0 dst port 80
...
14:07:24.835633 IP (tos 0x0, ttl 64, id 15549, offset 0, flags [DF], proto TCP (6), length 60)
kvmcentos.45022 > kvmubuntu.http: Flags [S], cksum 0x76d1 (incorrect -> 0x9a90), seq 1076682845, win 64240, options [mss 1460,sackOK,TS val 3110711737 ecr 0,nop,wscale 7], length 0
14:07:24.836511 IP (tos 0x0, ttl 64, id 15550, offset 0, flags [DF], proto TCP (6), length 52)
kvmcentos.45022 > kvmubuntu.http: Flags [.], cksum 0x76c9 (incorrect -> 0x51b3), ack 2952605173, win 502, options [nop,nop,TS val 3110711738 ecr 3247231251], length 0
14:07:24.836838 IP (tos 0x0, ttl 64, id 15551, offset 0, flags [DF], proto TCP (6), length 412)
kvmcentos.45022 > kvmubuntu.http: Flags [P.], cksum 0x7831 (incorrect -> 0xb0a2), seq 0:360, ack 1, win 502, options [nop,nop,TS val 3110711739 ecr 3247231251], length 360: HTTP, length: 360
GET / HTTP/1.1
Host: tipubuntu
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/115.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1
14:07:24.844920 IP (tos 0x0, ttl 64, id 15552, offset 0, flags [DF], proto TCP (6), length 52)
kvmcentos.45022 > kvmubuntu.http: Flags [.], cksum 0x76c9 (incorrect -> 0x4285), ack 3522, win 489, options [nop,nop,TS val 3110711747 ecr 3247231260], length 0
14:07:29.846014 IP (tos 0x0, ttl 64, id 15553, offset 0, flags [DF], proto TCP (6), length 52)
kvmcentos.45022 > kvmubuntu.http: Flags [F.], cksum 0x76c9 (incorrect -> 0x2eef), seq 360, ack 3522, win 501, options [nop,nop,TS val 3110716748 ecr 3247231260], length 0
14:07:29.846795 IP (tos 0x0, ttl 64, id 15554, offset 0, flags [DF], proto TCP (6), length 52)
kvmcentos.45022 > kvmubuntu.http: Flags [.], cksum 0x76c9 (incorrect -> 0x1b63), ack 3523, win 501, options [nop,nop,TS val 3110716749 ecr 3247236262], length 0
[root@kvmcentos ~]# tcpdump -v -n -w my.log dst port 80 -c 500
...
[root@kvmcentos ~]# ls my.log
my.log
[root@kvmcentos ~]# tcpdump -nr my.log | awk '{print root@aw:/#3}' | grep -oE '[0-9]{1,}\.[0-9]{1,}\.[0-9]{1,}\.[0-9]{1,}' | sort | uniq -c | sort -rn
reading from file my.log, link-type EN10MB (Ethernet), snapshot length 262144
dropped privs to tcpdump
6 tipkali